- J25
-
Gianluca Monaci,
Rafael S. Rezende,
Romain Deffayet,
Gabriela Csurka,
Guillaume Bono,
Hervé Déjean,
Stéphane Clinchant,
and
Christian Wolf.
RANa: Retrieval-Augmented Navigation.
In Transactions on Machine Learning Research (TMLR).
Methods for navigation based on large-scale learning typically treat each episode as a new problem, where the agent is spawned with a clean memory in an unknown environment. While these generalization capabilities to an unknown environment are extremely important, we claim that, in a realistic setting, an agent should have the capacity of exploiting information collected during earlier robot operations. We address this by introducing a new retrieval-augmented agent, trained with RL, capable of querying a database collected from previous episodes in the same environment and learning how to integrate this additional context information. We introduce a unique agent architecture for the general navigation task, evaluated on ObjectNav, ImageNav and Instance-ImageNav. Our retrieval and context encoding methods are data-driven and heavily employ vision foundation models (FM) for both semantic and geometric understanding. We propose new benchmarks for these settings and we show that retrieval allows zero-shot transfer across tasks and environments while significantly improving performance.
- J24
-
Théo Jaunet,
Corentin Kervadec,
Grigory Antipov,
Moez Baccouche,
Romain Vuillemot and
Christian Wolf.
VisQA: X-raying Vision and Language Reasoning in Transformers.
In IEEE Transactions on Visualization and Computer Graphics (Proceedings of VIS 2021).
Visual Question Answering systems target answering open-ended textual questions given input images. They are a testbed for learning high-level reasoning with a primary use in HCI, for instance assistance for the visually impaired. Recent research has shown that state-of-the-art models tend to produce answers exploiting biases and shortcuts in the training data, and sometimes do not even look at the input image, instead of performing the required reasoning steps. We present VisQA, a visual analytics tool that explores this question of reasoning vs. bias exploitation. It exposes the key element of state-of-the-art neural models -- attention maps in transformers. Our working hypothesis is that reasoning steps leading to model predictions are observable from attention distributions, which are particularly useful for visualization. The design process of VisQA was motivated by well-known bias examples from the fields of deep learning and vision-language reasoning and evaluated in two ways. First, as a result of a collaboration of three fields, machine learning, vision and language reasoning, and data analytics, the work lead to a direct impact on the design and training of a neural model for VQA, improving model performance as a consequence. Second, we also report on the design of VisQA, and a goal-oriented evaluation of VisQA targeting the analysis of a model decision process from multiple experts, providing evidence that it makes the inner workings of models accessible to users.
- J23
-
Théo Jaunet,
Romain Vuillemot and
Christian Wolf.
DRLViz: Understanding Decisions and Memory in Deep Reinforcement Learning.
In Computer Graphics Forum (Proceedings of Eurovis), 2020.
We present DRLViz, a visual analytics interface to interpret the internal memory of an agent (e.g. a robot) trained using deep reinforcement learning. This memory is composed of large temporal vectors updated when the agent moves in an environment and is not trivial to understand. It is often referred to as a black box as only inputs (images) and outputs (actions) are intelligible for humans. Using DRLViz, experts are assisted to interpret using memory reduction interactions, to investigate parts of the memory role when errors have been made, and ultimately to improve the agent training process. We report on several examples of use of DRLViz, in the context of video games simulators (ViZDoom) for a navigation scenario with item gathering tasks. We also report on experts evaluation using DRLViz, and applicability of DRLViz to other scenarios and navigation problems beyond simulation games, as well as its contribution to black box models interpret-ability and explain-ability in the field of visual analytics.
- J22
-
Tom Gillooly,
Nicolas Coltice and
Christian Wolf.
An anticipation experiment for plate tectonics.
In "Tectonics", 38(11):3916-3938, 2019.
Although plate tectonics has pushed the frontiers of geosciences in the past 50 years, it has legitimate limitations and among them we focus on both the absence of dynamics in the theory, and the difficulty of reconstructing tectonics when data is sparse. In this manuscript, we propose an anticipation experiment, proposing a singular outlook on plate tectonics in the digital era. We hypothesize that mantle convection models producing self-consistently plate-like behavior will capture the essence of the self-organisation of plate boundaries. Such models exist today in a preliminary fashion and we use them here to build a database of mid-ocean ridge and trench configurations. To extract knowledge from it we develop a machine learning framework based on Generative Adversarial Networks (GANs) that learns the regularities of the self-organisation in order to fill gaps of observations when working on reconstructing a plate configuration. The user provides the distribution of known ridges and trenches, the location of the region where observations lack, and our digital architecture proposes a horizontal divergence map from which missing plate boundaries are extracted. Our framework is able to prolongate and interpolate plate boundaries within an unresolved region, but fails to retrieve a plate boundary that would be completely contained in it. The attempt we make is certainly too early because geodynamic models need improvement and a larger amount of geodynamic model outputs, as independent as possible, is required. However, this work suggests applying such an approach to expand the capabilities of plate tectonics is within reach.
- J21
-
Pejman Rasti,
Christian Wolf and
Hugo Dorez,
Raphael Sablong,
Driffa Moussata,
Salma Samiei,
David Rousseau.
Machine Learning-Based Classification of the Health State of Mice Colon in Cancer Study from Confocal Laser Endomicroscopy.
In "Nature Scientific Reports 9", 2019.
In this article, we address the problem of the classification of the health state of the colon's wall of mice, possibly injured by cancer with machine learning approaches. This problem is essential for translational research on cancer and is a priori challenging since the amount of data is usually limited in all preclinical studies for practical and ethical reasons. Three states considered including cancer, health, and inflammatory on tissues. Fully automated machine learning-based methods are proposed, including deep learning, transfer learning, and shallow learning with SVM. These methods addressed different training strategies corresponding to clinical questions such as the automatic clinical state prediction on unseen data using a pre-trained model, or in an alternative setting, real-time estimation of the clinical state of individual tissue samples during the examination. Experimental results show the best performance of 99.93% correct recognition rate obtained for the second strategy as well as the performance of 98.49% which were achieved for the more difficult first case.
- J20
-
Ozgur Erkent,
Christian Wolf and
Christian Laugier.
End-to-End Learning of Semantic Grid Estimation Deep Neural Network with Occupancy Grids.
In "Unmanned Systems", 07(03):171-181, 2019.
We propose semantic grid, a spatial 2D map of the environment around an autonomous vehicle consisting of cells which represent the semantic information of the corresponding region such as car, road, vegetation, bikes, etc. It consists of an integration of an occupancy grid, which computes the grid states with a Bayesian filter approach, and semantic segmentation information from monocular RGB images, which is obtained with a deep neural network. The network fuses the information and can be trained in an end-to-end manner. The output of the neural network is refined with a conditional random field. The proposed method is tested in various datasets (KITTI dataset, Inria-Chroma dataset and SYNTHIA) and different deep neural network architectures are compared.
- J19
-
Bastien Moysset,
Christopher Kermorvant,
Christian Wolf.
Learning to detect, localize and recognize many text objects in document images from few examples.
In International Journal on Document Analysis and Recognition (IJDAR), 21(3):161–175, 2018.
The current trend in object detection and localization is to
learn predictions with high capacity deep neural networks
trained on a very large amount of annotated data and using
a high amount of processing power. In this work, we pro-
pose a new neural model which directly predicts bounding
box coordinates. The particularity of our contribution lies
in the local computations of predictions with a new form of
local parameter sharing which keeps the overall amount of
trainable parameters low. Key components of the model are
spatial 2D-LSTM recurrent layers which convey contextual
information between the regions of the image.
We show that this model is more powerful than the state
of the art in applications where training data is not as abun-
dant as in the classical configuration of natural images and
Imagenet/Pascal VOC tasks. We particularly target the de-
tection of text in document images, but our method is not
limited to this setting. The proposed model also facilitates
the detection of many objects in a single image and can deal
with inputs of variable sizes without resizing.
- J18
-
Emre Dogan,
Gonen Eren,
Christian Wolf,
Eric Lombardi,
Atilla Baskurt.
Multi-view pose estimation with mixtures-of-parts and adaptive viewpoint selection.
In IET Computer Vision, 12(4):403–411, 2018.
We propose a new method for human pose estimation which leverages information
from multiple views to impose a strong prior on articulated pose. The novelty
of the method concerns the types of coherence modelled. Consistency is
maximised over the different views through different terms modelling classical
geometric information (coherence of the resulting poses) as well as appearance
information which is modelled as latent variables in the global energy
function. Moreover, adequacy of each view is assessed and their contributions
are adjusted accordingly. Experiments on the HumanEva and UMPM datasets show
that the proposed method significantly decreases the estimation error compared
to single-view results.
- J17
-
Natalia Neverova,
Christian Wolf,
Florian Nebout,
Graham W. Taylor.
Hand Pose Estimation through Weakly-Supervised Learning of a Rich Intermediate Representation.
In Computer Vision and Image Understanding (CVIU) 167:56-67, 2017.
We propose a method for hand pose estimation based on a deep regressor trained on two different kinds of input. Raw depth data is fused with an intermediate representation in the form of a segmentation of the hand into parts. This intermediate representation contains important topological information and provides useful cues for reasoning about joint locations. The mapping from raw depth to segmentation maps is learned in a semi/weakly-supervised way from two different datasets: (i) a synthetic dataset created through a rendering pipeline including densely labeled ground truth (pixelwise segmentations); and (ii) a dataset with real images for which ground truth joint positions are available, but not dense segmentations. Loss for training on real images is generated from a patch-wise restoration process, which aligns tentative segmentation maps with a large dictionary of synthetic poses. The underlying premise is that the domain shift between synthetic and real data is smaller in the intermediate representation, where labels carry geometric and topological meaning, than in the raw input domain. Experiments on the NYU dataset show that the proposed training method decreases error on joints over direct regression of joints from depth data by 15.7%.
- J16
-
Eric Guerin,
Eric Galin,
Julie Digne,
Adrien Peytavie,
Christian Wolf,
Bedrich Benes,
Benoit Martinez.
Interactive Example-Based Terrain Authoring with Conditional Generative Adversarial Networks.
In Transactions on Graphics (SIGGRAPH Asia), 2017.
Authoring virtual terrains presents a challenge and there is a strong need for authoring tools
able to create realistic terrains with simple user-inputs and with high user control.
We propose an example-based authoring pipeline that uses a set of terrain synthesizers dedicated to specific tasks.
Each terrain synthesizer is a Conditional Generative Adversarial Network
trained by using real-world terrains and their sketched counterparts.
The training sets are built automatically with a view that the terrain synthesizers learn the generation from features that are easy to sketch. During the authoring process, the artist first creates a rough sketch of the main terrain features, such as rivers, valleys and ridges, and the algorithm automatically synthesizes a terrain corresponding to the sketch using the learned features of the training samples.
Moreover, an erosion synthesizer can also generate terrain evolution by erosion at a very low computational cost.
Our framework allows for an easy terrain authoring and provides a high level of realism for a minimum sketch cost.
We show various examples of terrain synthesis created by experienced as well as inexperienced users who are able to
design a vast variety of complex terrains in a very short time.
- J15
-
Damien Fourure,
Remi Emonet,
Elisa Fromont,
Damien Muselet,
Natalia Neverova,
Alain Trémeau,
Christian Wolf.
Multi-task, Multi-domain Learning: application to semantic segmentation and pose regression.
In Neurocomputing, 2017.
We present an approach that leverages multiple datasets annotated for different tasks (e.g., classification with different labelsets) to improve the predictive accuracy on each individual dataset.
Domain adaptation techniques can correct dataset bias but they are not applicable when the tasks differ, and they need to be complemented to handle multi-task settings.
We propose a new selective loss function that can be integrated into deep neural networks to exploit training data coming from multiple datasets annotated for related but possibly different label sets.
We show that the gradient-reversal approach for domain adaptation can be used in this setup to additionally handle domain shifts.
We also propose an auto-context approach that further captures existing correlations across tasks.
Thorough experiments on two types of applications (semantic segmentation and hand pose estimation) show the relevance of our approach in different contexts.
- J14
-
Natalia Neverova,
Christian Wolf,
Graham W. Taylor and
Florian Nebout.
ModDrop: adaptive multi-modal gesture recognition.
In IEEE Transactions on Pattern Analysis and Machine Intelligence - PAMI 38(8):1692-1706, 2016.
We present a method for gesture detection and localisation based on multi-scale and multi-modal deep learning. Each visual modality captures spatial information at a particular spatial scale (such as motion of the upper body or a hand), and the whole system operates at three temporal scales. Key to our technique is a training strategy which exploits: i) careful initialization of individual modalities; and ii) gradual fusion involving random dropping of separate channels (dubbed "ModDrop") for learning cross-modality correlations while preserving uniqueness of each modality-specific representation. We present experiments on the ChaLearn 2014 Looking at People Challenge gesture recognition track, in which we placed first out of 17 teams. Fusing multiple modalities at several spatial and temporal scales leads to a significant increase in recognition rates, allowing the model to compensate for errors of the individual classifiers as well as noise in the separate channels. Futhermore, the proposed ModDrop training technique ensures robustness of the classifier to missing signals in one or several channels to produce meaningful predictions from any number of available modalities. In addition, we demonstrate the applicability of the proposed fusion scheme to modalities of arbitrary nature by experiments on the same dataset augmented with audio.
- J13
-
Natalia Neverova,
Christian Wolf,
Griffin Lacey, Lex Fridman, Deepak Chandra, Brandon Barbello and
Graham W. Taylor.
Learning Human Identity from Motion Patterns.
In IEEE Access (4):1810-1820, 2016.
We present a large-scale study, exploring the capability of temporal deep neural networks in interpreting natural human kinematics and introduce the first method for active biometric authentication with mobile inertial sensors. At Google, we have created a first-of-its-kind dataset of human movements, passively collected by 1500 volunteers using their smartphones daily over several months. We (1) compare several neural architectures for efficient learning of temporal multi-modal data representations, (2) propose an optimized shift-invariant dense convolutional mechanism (DCWRNN) and (3) incorporate the discriminatively-trained dynamic features in a probabilistic generative framework taking into account temporal characteristics. Our results demonstrate, that human kinematics convey important information about user identity and can serve as a valuable component of multi-modal authentication systems.
- J12
-
Alaeddine Mihoub,
Gerard Bailly,
Christian Wolf and
Fréderic Elisei.
Graphical models for social behavior modeling in face-to face interaction.
In Pattern Recognition Letters (75):82-89, 2016.
The goal of this paper is to model the coverbal behavior of a subject involved in face-to-face social interactions. For this end, we present a multimodal behavioral model based on a Dynamic Bayesian Network (DBN). The model was inferred from multimodal data of interacting dyads in a specific scenario designed to foster mutual attention and multimodal deixis of objects and places in a collaborative task. The challenge for this behavioral model is to generate coverbal actions (gaze, hand gestures) for the subject given his verbal productions, the current phase of the interaction and the perceived actions of the partner. In our work, the structure of the DBN was learned from data, which revealed an interesting causality graph describing precisely how verbal and coverbal human behaviors are coordinated during the studied interactions. Using this structure, DBN exhibits better performances compared to classical baseline models such as Hidden Markov Models (HMMs) and Hidden Semi-Markov Models (HSMMs). We outperform the baseline in both measures of performance, i.e. interaction unit recognition and behavior generation. DBN also reproduces more faithfully the coordination patterns between modalities observed in ground truth compared to the baseline models.
- J11
-
Oya Celiktutan,
Christian Wolf,
Bülent Sankur and
Eric Lombardi.
Fast Exact Hyper-Graph Matching with Dynamic Programming for Spatio-Temporal Data.
In
Journal on Mathematical Imaging and Vision, pp. 1-21, 2015.
Graphs and hyper-graphs are frequently used to recognize complex and often non-rigid patterns in computer vision, either through graph matching or point-set matching with graphs. Most formulations resort to the minimization of a difficult energy function containing geometric or structural terms, frequently coupled with data attached terms involving appearance information. Traditional methods solve the minimization problem approximately, for instance re- sorting to spectral techniques. In this paper, we deal with the spatio-temporal data, for a concrete example, human actions in video sequences. In this context, we first make three realistic assumptions: (i) causality of human movements; (ii) sequential nature of human movements; and (iii) one-to-one mapping of time instants. We show that, under these assumptions, the correspondence problem can be decomposed into a set of subproblems such that each subproblem can be solved recursively in terms of the others, and hence an efficient exact minimization algorithm can be derived using dynamic programming approach. Secondly, we propose a special graphical structure which is elongated in time. We argue that, instead of approximately solving the original problem, a solution can be obtained by exactly solving an approximated problem. An exact minimization algorithm is derived for this structure and successfully applied to action recognition in two settings: video data and Kinect coordinate data.
- J10
-
Alaeddine Mihoub,
Gerard Bailly,
Christian Wolf and
Fréderic Elisei.
Learning multimodal behavioral models for face-to-face social interaction.
In
Journal on Multimodal User Interfaces, (9):3, pp 195-210, 2015.
The aim of this paper is to model multimodal perception-action loops of human behavior in face-to-face interactions. The long-term goal of this research is to give artificial agents social skills to engage believable interactions with human interlocutors. To this end, we propose trainable behavioral models that generate optimal actions given others’ perceived actions and joint goals. We first compare sequential models - in particular Discrete Hidden Markov Models (DHMMs) - with standard classifiers (SVMs and Decision Trees). We propose a modification of the initialization of the DHMMs in order to better capture the recurrent structure of the sensory-motor states. We show that the explicit state duration modeling by Hidden Semi Markov Models (HSMMs) improves prediction performance. We applied these models to parallel speech and gaze data collected from interacting dyads. The challenge was to predict the gaze of one subject given the gaze of the interlocutor and the voice activity of both. For both HMMs and HSMMs the Short-Time Viterbi concept is used for incremental decoding and generation. For the proposed models we evaluated objectively many properties in order to go beyond pure classification performance. Results show that while Incremental Discrete HMMs (IDHMMs) were more efficient than classic classifiers, the Incremental Discrete HSMMs (IDHSMMs) give best performance. This result emphasizes the relevance of state duration modeling.
- J9
-
Christian Wolf,
Eric Lombardi,
Julien Mille,
Oya Celiktutan,
Mingyuan Jiu,
Emre Dogan,
Gonen Eren,
Moez Baccouche,
Emmanuel Dellandréa,
Charles-Edmond Bichot,
Christophe Garcia,
Bülent Sankur.
Evaluation of video activity localizations integrating quality and quantity measurements.
In
Computer Vision and Image Understanding
(127):14-30, 2014.
Evaluating the performance of computer vision algorithms is classically done by reporting classification error or accuracy, if the problem at hand is the classification of an object in an image, the recognition of an activity in a video or the categorization and labeling of the image or video. If in addition the detection of an item in an image or a video, and/or its localization are required, frequently used metrics are Recall and Precision, as well as ROC curves. These metrics give quantitative performance values which are easy to understand and to interpret even by non-experts. However, an inherent problem is the dependency of quantitative performance measures on the quality constraints that we need impose on the detection algorithm. In particular, an important quality parameter of these measures is the spatial or spatio-temporal overlap between a ground-truth item and a detected item, and this needs to be taken into account when interpreting the results.
We propose a new performance metric addressing and unifying the qualitative and quantitative aspects of the performance measures. The performance of a detection and recognition algorithm is illustrated intuitively by performance graphs which present quantitative performance values, like Recall, Precision and F-Score, depending on quality constraints of the detection. In order to compare the performance of different computer vision algorithms, a representative single performance measure is computed from the graphs, by integrating out all quality parameters. The evaluation method can be applied to different types of activity detection and recognition algorithms. The performance metric has been tested on several activity recognition algorithms participating in the ICPR 2012 HARL competition.
- J8
-
Mingyuan Jiu,
Christian Wolf,
Graham W. Taylor and
Atilla Baskurt.
Human body part estimation from depth images via spatially-constrained deep learning.
In
Pattern Recognition Letters 50(1):122-129, 2014.
Object recognition, human pose estimation and scene recognition are applications which are
frequently solved through a decomposition into a collection of parts. The resulting local
representation has significant advantages, especially in the case of occlusions and when
the subject is non-rigid. Detection and recognition require modelling the appearance of the
different object parts as well as their spatial layout. This representation has been particularly
successful in body part estimation from depth images.
Integrating the spatial layout of parts may require the minimization of complex energy functions.
This is prohibitive in most real world applications and therefore often omitted. However,
ignoring the spatial layout puts all the burden on the classifier, whose only available
information is local appearance. We propose a new method to integrate spatial layout into
parts classification without costly pairwise terms during testing.
Spatial relationships are exploited in the training algorithm, but not during testing.
As with competing methods, the proposed method classifies pixels independently, which
makes real-time processing possible. We show that training a classifier with spatial
relationships increases generalization performance when compared to classical training
minimizing classification error on the training set. We present an application to
human body part estimation from depth images.
- J7
-
Mingyuan Jiu,
Christian Wolf,
Christophe Garcia and
Atilla Baskurt.
Supervised learning and codebook optimization for bag of words models.
In
Cognitive Computation, Springer Verlag,
(4):409-419, 2012.
In this paper, we present a novel approach for supervised codebook learning and optimization for bag of words models. This type of models is frequently used in visual recognition tasks like object class recognition or human action recognition. An entity is represented as a histogram of codewords, which are traditionally clustered with unsupervised methods like \textit{k}-means or random forests, and then classified in a supervised way. We propose a new supervised method for joint codebook creation and class learning, which learns the cluster centers of the codebook in a goal-directed way using the class labels of the training set. As a result, the codebook is highly correlated to the recognition problem, leading to a more discriminative codebook. We propose two different learning algorithms, one based on error backpropagation and one based on cluster label reassignment. We apply the proposed method to human action recognition from video sequences and evaluate it on the KTH dataset, reporting very promising results. The proposed technique allows to improve the discriminative power of an unsupervised learned codebook, or to keep the discriminative power while decreasing the size of the learned codebook, thus decreasing the computational complexity due to the nearest neighbor search.
- J6
-
Vincent Vidal,
Christian Wolf,
Florent Dupont.
Combinatorial Mesh Optimization,
In
The Visual Computer,
28(5):511-525, 2012.
A new mesh optimization framework for 3D triangular surface meshes is presented, which formulates the task as an energy minimization problem in the same spirit as in Hoppe et al. [1]. The desired mesh properties are controlled through a global energy function including data attached terms measuring the fidelity to the original mesh, shape potentials favoring high quality triangles and connectivity as well as budget terms controlling the sampling density. The optimization algorithm modifies mesh connectivity as well as the vertex positions. Solutions for the vertex repositioning step are obtained by a discrete graph cut algorithm examining global combinations of local candidates. Results on various 3D meshes compare favorably to recent state-of-the-art algorithms. Applications consist in optimizing triangular meshes and in simplifying meshes, while maintaining high mesh quality. Targeted areas are the improvement of the accuracy of numerical simulations, the convergence of numerical schemes, improvements of mesh rendering (normal field smoothness) or improvements of the geometric prediction in mesh compression techniques.
- J5
-
Christian Wolf.
Document Ink bleed-through removal with two hidden Markov random fields and a single observation field.
In IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 32(3):431-447, 2010.
We present a new method for blind document bleed through removal based on separate Markov Random Field (MRF) regularization for the recto and for the verso side, where separate priors are derived from the full graph. The segmentation algorithm is based on Bayesian Maximum a Posteriori (MAP) estimation. The advantages of this separate approach are the adaptation of the prior to the contents creation process (e.g. superimposing two hand written pages), and the improvement of the estimation of the recto pixels through an estimation of the verso pixels covered by recto pixels; Moreover, the formulation as a binary labeling problem with two hidden labels per pixels naturally leads to an efficient optimization method based on the minimum cut/maximum flow in a graph. The proposed method is evaluated on scanned document images from the 18th century, showing an improvement of character recognition results compared to other restoration methods.
- J4
-
Christian Wolf and Gérald Gavin.
Inference and parameter estimation on hierarchical belief networks for image segmentation.
In Neurocomputing 73(4-6):563-569, 2010.
We introduce a new causal hierarchical belief network for image segmentation. Contrary to classical tree structured (or pyramidal) models, the factor graph of the network contains cycles. Each level of the hierarchical structure features the same number of sites as the base level and each site on a given level has several neighbors on the parent level. Compared to tree structured models, the (spatial) random process on the base level of the model is stationary which avoids known drawbacks, namely visual artifacts in the segmented image.
We propose different parameterizations of the conditional probability distributions governing the transitions between the image levels. A parametric distribution depending on a single parameter allows the design of a fast inference algorithm on graph cuts, whereas for arbitrary distributions, we propose inference with loopy belief propagation. The method is evaluated on scanned documents, showing an improvement of character recognition results compared to other methods.
- J3
-
Christian Wolf and
Jean-Michel Jolion.
Object count/Area Graphs for the Evaluation of Object Detection and Segmentation Algorithms,
In
International Journal on Document Analysis and Recognition
, 8(4):280-296, 2006.
Evaluation of object detection algorithms is a non-trivial task: a detection result is usually
evaluated by comparing the bounding box of the detected object with the bounding box of the
ground truth object. The commonly used precision and recall measures are computed from the overlap
area of these two rectangles. However, these measures have several drawbacks: they don't give
intuitive information about the proportion of the correctly detected objects and the number of
false alarms, and they cannot be accumulated across multiple images without creating ambiguity
in their interpretation. Furthermore, quantitative and qualitative evaluation is often mixed
resulting in ambiguous measures.
In this paper we propose a new approach which tackles these problems. The performance of a
detection algorithm is illustrated intuitively by performance graphs which present object level
precision and recall depending on constraints on detection quality. In order to compare
different detection algorithms, a representative single performance value is computed from the
graphs. The influence of the test database on the detection performance is illustrated by
performance/generality graphs. The evaluation method can be applied to different types of object
detection algorithms. It has been tested on different text detection algorithms, among which are
the participants of the ICDAR 2003 text detection competition.
@Article{WolfIJDAR2006,
Author = {C. Wolf and J.-M. Jolion},
Title = {Object count/Area Graphs for the Evaluation of Object Detection and Segmentation Algorithms},
Journal = {International Journal on Document Analysis and Recognition},
year = {2006},
volume = {8},
number = {4},
pages = {280-296}
}
- J2
-
S.M. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong, R. Young,
K. Ashida, H. Nagai, M. Okamoto, H. Yamamoto, H. Miyao, J. Zhu, W. Ou,
C. Wolf,
J.-M. Jolion,
L. Todoran, M. Worring,
et X. Lin.
ICDAR 2003 Robust Reading Competitions: Entries, Results and
Future Directions
International Journal on Document Analysis and Recognition (IJDAR),
7(2-3):105-122, 2005
(Special Issue on Camera-based Text and Document Recognition)
This paper describes the robust reading competitions for ICDAR 2003. With the rapid
growth in research over the last few years on recognizing text in natural scenes,
there is an urgent need to establish some common benchmark datasets, and
gain a clear understanding of the current state of the art. We use the term robust
reading to refer to text images that are beyond the capabilities of current
commercial OCR packages. We chose to break down the robust reading problem into
three sub-problems, and run competitions for each stage, and also a competition for
the best overall system. The sub-problems we chose were text locating, character
recognition and word recognition. By breaking down the problem in this way, we hoped
to gain a better understanding of the state of the art in each of the sub-problems.
Furthermore, our methodology involved storing detailed results of applying each
algorithm to each image in the data sets, allowing researchers to study in depth the
strengths and weaknesses of each algorithm. The text locating contest was the only
one to have any entries. We give a brief description of each entry, and present the
results of this contest, showing cases where the leading entries succeed and fail.
We also describe an algorithm for combining the outputs of the individual text
locaters, and show how the combination scheme improves on any of the individual
systems.
- J1
-
Christian
Wolf and Jean-Michel Jolion.
Extraction and Recognition of Artificial Text in Multimedia Documents.
Pattern Analysis and Applications,
6(4):309-326, 2003.
The systems currently available for content based image and video retrieval
work without semantic knowledge, i.e. they use image processing methods to
extract low level features of the data. The similarity obtained by these
approaches does not always correspond to the similarity a human user would expect.
A way to include more semantic knowledge into the
indexing process is to use the text included in the images and video sequences.
It is rich in information but easy to use, e.g. by key word based queries. In
this paper we present an algorithm to localize artificial text in images and
videos using a measure of accumulated gradients and morphological processing.
The quality of the localized text is improved by robust multiple frame integration.
A new technique for the binarization of the text boxes based on a criterion
maximizing local contrast is proposed. Finally, detection and OCR results for a
commercial OCR are presented, justifying the choice of the binarization technique
@Article{WolfPAA03,
Author = {C. Wolf and J.-M. Jolion},
Title = {Extraction and {R}ecognition of {A}rtificial {T}ext in {M}ultimedia {D}ocuments},
Journal = {Pattern {A}nalysis and {A}pplications},
year = {2003},
volume = {6},
number = {4},
pages = {309-326}
}
- c42
-
Damien Fourure,
Remi Emonet,
Elisa Fromont,
Damien Muselet,
Alain Trémeau,
Christian Wolf.
Semantic Segmentation via Multi-task, Multi-domain Learning
In joint IAPR International Workshops on Structural and Syntactic Pattern Recognition (SSPR 2016) and Statistical Techniques in Pattern Recognition (SPR 2016).
We present an approach that leverages multiple datasets possibly
annotated using different classes to improve
the semantic segmentation accuracy on each
individual dataset. We propose a new
selective loss function that can be integrated into deep
networks to exploit training data coming from multiple datasets with
possibly different tasks (e.g., different label-sets). We show how
the gradient-reversal approach for domain adaptation can be used in this setup.
Thorought experiments on semantic segmentation applications show the relevance of our approach.
- c41
-
Bastien Moysset,
Jérome Louradour,
Christopher Kermorvant,
Christian Wolf.
Learning text-line localization with shared and local regression neural networks.
In International Conference on Frontiers in Handwriting Recognition, 2016.
Text line detection and localisation is a crucial step for full page document analysis, but still suffers from heterogeneity of real life documents. In this paper, we present a novel approach for text line localisation based on Convolutional Neural Networks and Multidimensional Long Short-Term Memory cells as a regressor in order to predict the coordinates of the text line bounding boxes directly from the pixel values. Targeting typically large images in document image analysis, we propose a new model using weight sharing over local blocks. We compare two strategies: directly predicting the four coordinates or predicting lower-left and upper-right points separately followed by matching. We evaluate our work on the highly unconstrained Maurdor dataset and show that our method outperforms both other machine learning and image processing methods.
- c40
-
Damien Fourure,
Remi Emonet,
Elisa Fromont,
Damien Muselet,
Alain Trémeau,
Christian Wolf.
Mixed pooling Neural Networks for Color Constancy.
In International Conference on Image Processing (ICIP), 2016.
Color constancy is the ability of the human visual system to perceive constant colors for a surface despite changes in the spectrum of the illumination. In computer vision, the main approach consists in estimating the illuminant color and then to remove its impact on the color of the objects. Many image processing algorithms have been proposed to tackle this prob- lem automatically. However, most of these approaches are handcrafted and mostly rely on strong empirical assumptions, e.g., that the average reflectance in a scene is gray. State- of-the-art approaches can perform very well on some given datasets but poorly adapt on some others. In this paper, we have investigated how neural networks-based approaches can be used to deal with the color constancy problem. We have proposed a new network architecture based on existing suc- cessful hand-crafted approaches and a large number of im- provements to tackle this problem by learning a suitable deep model. We show our results on most of the standard bench- marks used in the color constancy domain.
- c39
-
Bastien Moysset,
Christopher Kermorvant,
Christian Wolf,
Jérome Louradour.
Paragraph text segmentation into lines with Recurrent Neural Networks.
In International Conference on Document Analysis and Recognition (ICDAR), 2015.
The detection of text lines, as a first processing step,
is critical in all Text Recognition systems.
State-of-the-art methods to locate lines of text
are based on handcrafted heuristics fine-tuned by the Image Processing Community's experience.
They succeed under certain constraints; for instance the background has to be roughly uniform.
We propose to use more ``agnostic'' Machine Learning-based approaches to address text line location.
The main motivation is to be able to process either damaged documents,
or flows of documents with a high variety of layouts and other characteristics.
A new method is presented in this work, inspired by the latest generation of optical models used for Text Recognition,
namely Recurrent Neural Networks.
As these models are sequential, a column of text lines in our application plays here the same role as a line of characters in more traditional text recognition settings.
A key advantage of the proposed method over other data-driven approaches is that
compiling a training dataset does not require labeling line boundaries:
only the number of lines are required for each paragraph.
Experimental results show that our approach gives similar or better results than traditional handcrafted approaches, with little engineering efforts and less hyper-parameter tuning.
- c38
-
Bastien Moysset,
Pierre Adam,
Christian Wolf,
Jérome Louradour.
Space Displacement Localization Neural Networks to locate origin points of handwritten text lines in historical documents.
In ICDAR Workshop on Historical Document Imaging and Processing, 2015.
We describe a new method for detecting and localizing multiple objects in an image using context aware deep neural networks. Common architectures either proceed locally per pixel-wise sliding-windows, or globally by predicting object localizations for a full image. We improve on this by training a semi-local model to detect and localize objects inside a large image region, which covers an object or a part of it. Context knowledge is integrated, combining multiple predictions for different regions through a spatial context layer modeled as an LSTM network. The proposed method is applied to a complex problem in historical document image analysis, where we show that is capable of robustly detecting text lines in the images from the ANDAR-TL competition. Experiments indicate that the model can cope with difficult situations and reach the state of the art in Vision such as other deep models.
- c37
-
Emre Dogan,
Gonen Eren,
Christian Wolf,
Atilla Baskurt.
Activity recognition with volume motion templates and histograms of 3D gradients.
In International Conference on Image Processing (ICIP), 2015.
We propose a new method for activity recognition based on a view independent representation of human motion. Robust 3D volume motion templates (VMTs) are calculated from tracklets. View independence is achieved through a rotation with respect to a canonical orientation. From this volumes, features based on 3D gradients are extracted, projected to a codebook and pooled into a bags-of-words model classified with an SVM classifier. Experiments show that the method outperforms the original HoG3D method.
- c36
-
Leslie Guillaume,
Véronique Aubergé,
Romain Magnani, Frédéric Aman, Cécile Cottier, Yuko Sasa,
Christian Wolf,
Florian Nebout,
Natalia Neverova,
Nicolas Bonnefond, Amaury Negre, Liliya Tsvetanova, Maxence Girard-Rivier.
Gestural HRI in an ecological dynamic experiment: the GEE corpus based approach for the Emox robot.
In International Workshop on Advanced Robotics and its Social Impacts
(ARSO), 2015.
As part of a human-robot interaction project, the gestural modality is one of a possible way to communicate. In order to develop a relevant gesture recognition system associated to a smart home butler robot, our methodology is based on an IQ game-like Wizard of Oz experiment to collect spontaneous and implicitly produced gestures in an ecological context where the robot is the referee of the game. These gestures are compared with explicitly produced gestures to determine a relevant ontology of gestures. This preliminary qualitative analysis will be the base to build a big data corpus in order to optimize acceptance of the gesture dictionary in coherence with the “socio-affective glue” dynamics.
- c35
-
Gerard Bailly,
Alaeddine Mihoub,
Christian Wolf and
Frédéric Elisei.
Learning joint multimodal behaviors for face-to-face interaction: performance & properties of statistical models.
In HRI Workshop on Behavior Coordination between Animals, Humans, and Robots,
2015.
We evaluate here the ability of statistical models,
namely Hidden Markov Models (HMMs) and Dynamic Bayesian Networks
(DBNs), in capturing the interplay and coordination
between multimodal behaviors of two individuals involved in
a face-to-face interaction. We structure the intricate sensory-mot
or coupling of the joint multimodal scores by segmenting the whole
interaction into so-called interaction units (IU). We show that
the proposed statistical models are able to capture the natural
dynamics of the interaction and that DBNs are particularly suitable
for reproducing original distributions of so-called coordination histograms.
- c34
-
Elisa Fromont,
Remi Emonet,
Taygun Kekec,
Alain Trémeau,
Christian Wolf.
Contextually Constrained Deep Networks for Scene Labeling.
In British Machine Vision Conference (BMVC), 2014.
Learning using deep learning architectures is a difficult problem: the complexity of
the prediction model and the difficulty of solving non-convex optimization problems inherent in most learning algorithms can both lead to overfitting phenomena and bad local optima. To overcome these problems we would like to constraint parts of the network using some semantic context to 1) control its capacity while still allowing complex func- tions to be learned 2) obtain more meaningful layers. We first propose to learn a weak convolutional network which would provide us rough label maps over the neighborhood of a pixel. Then, we incorporate this weak learner in a bigger network. This iterative process aims at increasing the interpretability by constraining some feature maps to learn precise contextual information. Using Stanford and SIFT Flow scene labeling datasets,
we show how this contextual knowledge improves accuracy of state-of-the-art architectures. The approach is generic and can be applied to similar networks where contextual cues are available at training time.
- c33
-
Natalia Neverova,
Christian Wolf,
Graham W. Taylor,
Florian Nebout.
Hand segmentation with structured convolutional learning
In Asian Conference on Computer Vision (ACCV), 2014.
The availability of cheap and effective depth sensors has resulted
in recent advances in human pose estimation and tracking. Detailed
estimation of hand pose, however, remains a challenge since fingers
are often occluded and may only represent just a few
pixels. Moreover, labelled data is difficult to obtain. We propose a
deep learning based-approach for hand pose estimation, targeting
gesture recognition, that requires very little labelled data. It
leverages both unlabeled data and synthetic data from
renderings. The key to making it work is to integrate structural
information not into the model architecture, which would slow down
inference, but into the training objective. We show that adding
unlabelled real-world samples significantly improves results
compared to a purely supervised setting.
- c32
-
Natalia Neverova,
Christian Wolf,
Graham W. Taylor,
Florian Nebout.
Multi-scale deep learning for gesture detection and localization
In ECCV ChaLearn Workshop on Looking at People, 2014.
(This paper describes the winning entry of the ChaLearn 2014 gesture recognition competition)
We present a method for gesture detection and localization
based on multi-scale and multi-modal deep learning. Each visual
modality captures spatial information at a particular spatial scale
(such as motion of the upper body or a hand), and the whole system
operates at two temporal scales. Key to our technique is a
training strategy which exploits i) careful initialization of
individual modalities; and ii) gradual fusion of modalities from strongest to weakest cross-modality
structure. We present experiments on the "ChaLearn 2014 Looking
at People Challenge" gesture recognition track, in which we placed
first out of 17 teams.
- c31
-
Alaeddine Mihoub,
Gerard Bailly and
Christian Wolf.
Modeling Perception-Action Loops: Comparing Sequential Models with Frame-Based Classifiers.
In ACM Human-Agent Interaction,
2014.
Modeling multimodal perception-action loops in face-to- face interactions is a crucial step in the process of building sensory-motor behaviors for social robots or users-aware Embodied Conversational Agents (ECA). In this paper, we compare trainable behavioral models based on sequential models (HMMs) and classifiers (SVMs and Decision Trees) inherently inappropriate to model sequential aspects. These models aim at giving pertinent perception/action skills for robots in order to generate optimal actions given the perceived actions of others and joint goals. We applied these models to parallel speech and gaze data collected from interacting dyads. The challenge was to predict the gaze of one subject given the gaze of the interlocutor and the voice activity of both. We show that Incremental Discrete HMM (IDHMM) generally outperforms classifiers and that injecting input context in the modeling process significantly improves the performances of all algorithms.
- c30
-
Simon Gay,
Olivier Georgeon,
Christian Wolf.
Autonomous object modeling based on affordances for spatial organization of behavior.
In International joint conference on development and learning and on epigenetic robotics, 2014.
We present an architecture for self-motivated agents to organize their behaviors in space according to possibilities of interactions afforded by initially unknown objects. The long-term goal is to design agents that construct their own knowledge of objects through experience, rather than exploiting
precoded knowledge. Self-motivation is defined here as a tendency to experiment and to respond to behavioral opportunities afforded by the environment. Some interactions have predefined valences that specify inborn behavioral preferences. Over time, the agent learns the relation between its perception of objects and the interactions that they afford, in the form of data structures, called signatures of interaction, which encode the minimal spatial configurations that afford an interaction. The agent keeps track of enacted interactions in a topological spatial memory, to recognize and localize subsequent possibilities of interaction (through their signatures) afforded by surrounding objects. Experiments with a simulated agent and a robot show that they learn to navigate in their environment, taking into account multiple surrounding objects, reaching or avoiding objects according to the valence of the interactions that they afford.
- c29
-
Natalia Neverova,
Christian Wolf,
Giulio Paci,
Giacomo Sommavilla,
Graham W. Taylor,
Florian Nebout.
A multi-scale approach to gesture detection and recognition.
In ICCV Workshop on Understanding Human Activities: Context and Interactions, 2013.
We propose a generalized approach to human gesture recognition based on multiple data modalities such as depth video, articulated pose and speech. In our system, each gesture is decomposed into large-scale body motion and local subtle movements such as hand articulation. The idea of learning at multiple scales is also applied to the temporal dimension, such that a gesture is considered as a set of characteristic motion impulses, or dynamic poses. Each modality is first processed separately in short spatio-temporal blocks, where discriminative data-specific features are either manually extracted or learned. Finally, we employ a Recurrent Neural Network for modeling large-scale temporal dependencies, data fusion and ultimately gesture classification.
Our experiments on the 2013 Challenge on Multi-modal Gesture Recognition dataset have demonstrated that using multiple modalities at several spatial and temporal scales leads to a significant increase in performance allowing the model to compensate for errors of individual classifiers as well as noise in the separate channels.
- c28
-
Oya Celiktutan,
Akgül Ceyhun burak,
Christian Wolf and
Bülent Sankur.
Graph-Based Analysis of Physical Exercise Actions.
In the Proceedings of the ACM Multimedia Workshop on Multimedia Indexing and Information Retrieval for Healthcare, 2013.
In this paper, we develop a graph-based method to align two dynamic sequences, and apply it to both action recognition tasks as well as to the objective quantification of the goodness of the action performance. The automated measurement of “action quality" has potential to be used to monitor action imitations, for example, during a physical therapy. We seek matches between a query sequence and model sequences selected with graph mining. The best matches are obtained through minimizing an energy function that jointly measures space and time domain discrepancies. This graph discrepancy measure has been used for recognizing actions, for separating acceptable and unacceptable action performances, or as a continuous quantification of the action performance goodness. Experimental evaluations demonstrate the improved results of our scheme vis-à-vis its nearest competitors. Furthermore, a plausible relationship has been obtained between action perturbation, given by the joint noise variances, and quality measure, given by matching energies averaged over a sequence.
- c27
-
Olivier Georgeon,
Christian Wolf,
Simon Gay.
An Enactive Approach to Autonomous Agent and Robot Learning.
In the Proceedings of the international joint conference on development and learning and on epigenetic robotics, 2013.
A novel way to model autonomous learning in artificial agents and robots is introduced, called an Enactive Markov Decision Process (EMDP). An EMDP keeps perception and action embedded within sensorimotor schemes rather than dissociated. On each decision cycle, the agent tries to enact a sensorimotor scheme, and the environment informs the agent whether it was indeed enacted or whether another sensorimotor scheme was enacted instead. This new modeling approach leads to implementing a new form of self-motivation called interactional motivation. An EMDP learning algorithm is presented. Results show that this algorithm allows the agent to develop active perception as it learns to master the sensorimotor contingences afforded by its coupling with the environment.
- c26
-
Mingyuan Jiu,
Christian Wolf,
Atilla Baskurt.
Integrating spatial layout of object parts into classification without pairwise terms: application to fast body parts estimation from depth images.
In the Proceedings of the international conference on computer vision theory and applications (Visapp), oral presentation, 2013.
Object recognition or human pose estimation methods often resort to a decomposition into a collection of parts. This local representation has significant advantages, especially in case of occlusions and when the “object” is non-rigid. Detection and recognition requires modelling the appearance of the different object parts as well as their spatial layout. The latter can be complex and requires the minimization of complex energy functions, which is prohibitive in most real world applications and therefore often omitted. However, ignoring the spatial layout puts all the burden on the classifier, whose only available information is local appearance. We propose a new method to integrate the spatial layout into the parts classification without costly pairwise terms. We present an application to body parts classification for human pose estimation.
- c25
-
Alaeddine Mihoub,
Gerard Bailly and
Christian Wolf.
Social behavior modeling based on Incremental Discrete Hidden Markov Models.
In the Proceedings of the International Workshop on Human Behavior Understanding,
2013.
Modeling multimodal face-to-face interaction is a crucial step in the process of building
social robots or users-aware Embodied Conversational Agents (ECA). In this context, we present
a novel approach for human behavior analysis and generation based on what we called
“Incremental Discrete Hidden Markov Model” (IDHMM). Joint multimodal activities of
interlocutors are first modeled by a set of DHMMs that are specific to supposed joint
cognitive states of the interlocutors. Respecting a task-specific syntax, the IDHMM is
then built from these DHMMs and split into i) a recognition model that will determine
the most likely sequence of cognitive states given the multimodal activity of the
interlocutor, and ii) a generative model that will compute the most likely activity
of the speaker given this estimated sequence of cognitive states. Short-Term Viterbi
(STV) decoding is used to incrementally recognize and generate behavior.
The proposed model is applied to parallel speech and gaze data of interacting dyads.
- c24
-
Moez Baccouche,
Frank Mamalet
Christian Wolf,
Christophe Garcia,
Atilla Baskurt
Spatio-Temporal Convolutional Sparse Auto-Encoder for Sequence Classification.
In the Proceedings of the British Machine Vision Conference (BMVC), oral presentation, 2012.
We present in this paper a novel learning-based approach for video sequence classification. Contrary to the dominant methodology, which relies on hand-crafted features that are manually engineered to be optimal for a specific task, our neural model automatically learns a sparse shift-invariant representation of the local 2D+t salient information, without any use of prior knowledge. To that aim, a spatio-temporal convolutional sparse auto-encoder is trained to project a given input in a feature space, and to reconstruct it from its projection coordinates. Learning is performed in an unsupervised manner by minimizing a global parametrized objective function. The sparsity is ensured by adding a sparsifying logistic between the encoder and the decoder, while the shift-invariance is handled by including an additional hidden variable to the objective function. The temporal evolution of the obtained sparse features is learned by a long short-term memory recurrent neural network rained to classify each sequence. We show that, since the feature learning process is problem-independent, the model achieves outstanding performances when applied to two different problems, namely human action and facial expression recognition. Obtained results are superior to the state of the art on the GEMEP-FERA dataset and among the very best on the KTH dataset.
- c23
-
Moez Baccouche,
Frank Mamalet
Christian Wolf,
Christophe Garcia,
Atilla Baskurt
Sparse Shift-Invariant Representation of Local 2D Patterns and Sequence Learning for Human Action Recognition
in the Proceedings of the IEEE International Conference on Pattern Recognition (ICPR), oral presentation, 2012.
Most existing methods for action recognition mainly rely on manually engineered features which, despite their good performances, are highly problem dependent. We propose in this paper a fully automated model, which learns to classify human actions without using any prior knowledge. A convolutional sparse auto- encoder learns to extract sparse shift-invariant representations of the 2D local patterns present in each video frame. The evolution of these mid-level features is learned by a Recurrent Neural Network trained to classify each sequence. Experimental results on the KTH dataset show that the proposed approach outperforms existing models which rely on learned-features, and gives comparable results with the best related works.
- c22
-
Vincent Vidal,
Christian Wolf,
Florent Dupont
Mesh Segmentation and Global 3D Model Extraction.
Symposium on Geometry Processing, Poster, 2012.
This paper presents a method for segmenting noisy 2-manifold meshes based on a decomposition into local shape primitives maximizing global coherence. This technique works by partitioning the input mesh into regions which can be approximated by a simple geometrical primitive such as a plane, a sphere or a cylinder. The partitioning is guided by robust shape extractions based on RANSAC sampling and the final decision to keep a 3D model into the final decomposition is based on a global graphical model which involves spatial and label cost priors. Obtained segmentations on noisy mesh models outperform other approaches in terms of region contour smoothness and consistency with mechanical object decomposition. Applications of this work are reverse engineering, mesh structure analysis, mesh feature enhancement, noise removal, mesh compression, piecewise approximation of mesh geometry (points, normals, curvatures), and remeshing.
- c20
-
Oya Celiktutan,
Christian Wolf and
Bülent Sankur,
Eric Lombardi
Real-Time Exact Graph Matching with Application in Human Action Recognition
In International Workshop on Human Behavior Understanding,
Istanbul, 2012.
Graph matching is one of the principal methods to formulate the correspondence between two set of points in computer vision and pattern recognition. Most formulations are based on the minimization of a difficult energy function which is known to be NP-hard. Traditional methods solve the minimization problem approximately. In this paper, we derive an exact minimization algorithm and successfully applied to action recognition in videos. In this context, we take advantage of special properties of the time domain, in particular causality and the linear order of time, and propose a new spatio-temporal graphical structure. We show that a better solution can be obtained by exactly solving an approximated problem instead of approximately solving the original problem.
- c19
-
Moez Baccouche,
Frank Mamalet
Christian Wolf,
Christophe Garcia and
Atilla Baskurt,
Sequential Deep Learning for Human Action Recognition,
In the Proceedings of the International Workshop on Human Behavior Understanding: Inducing Behavioral Change, 2011. Oral presentation.
We propose in this paper a fully automated deep model, which learns to classify human actions without using any prior knowledge. The first step of our scheme, based on the extension of Convolutional Neural Networks to 3D, automatically learns spatio-temporal features. A Recurrent Neural Network is then trained to classify each sequence considering the temporal evolution of the learned features for each timestep. Experimental results on the KTH dataset show that the proposed approach outperforms existing deep models, and gives comparable results with the best related works.
- c18
-
Vincent Vidal,
Christian Wolf,
Florent Dupont
Robust feature line extraction on CAD triangular meshes,
in the Proceedings of the International Conference on Computer Graphics Theory and Applications, oral presentation, 2011
- c17
-
Christian Wolf and
Jean-Michel Jolion
Integrating a discrete motion model into GMM based background subtraction,
In the Proceedings of the IEEE International Conference on Pattern Recognition, oral presentation, 2010.
GMM based algorithms have become the de facto standard for background subtraction in video sequences, mainly because of their ability to track multiple background distributions, which allows them to handle complex scenes including moving trees, flags moving in the wind etc. However, it is not always easy to determine which distributions of the mixture belong to the background and which distributions belong to the foreground, which disturbs the results of the labeling process for each pixel. In this work we tackle this problem by taking the labeling decision together for all pixels of several consecutive frames minimizing a global energy function taking into account spatial and temporal relationships. A discrete approximative optical-flow like motion model is integrated into the energy function and solved with Ishikawa's convex graph cuts algorithm.
- c16
-
Anh-Phong Ta,
Christian Wolf,
Guillaume Lavoué,
Atilla Baskurt and
Jean-Michel Jolion
Pairwise features for human action recognition,
in the Proceedings of the IEEE International Conference on Pattern Recognition, 2010.
Existing action recognition approaches mainly rely on the discriminative power of individual local descriptors extracted from spatio-temporal interest points (STIP), while the geometric relationships among the local features are ignored. This paper presents new features, called pairwise features (PWF), which encode both the appearance and the spatio-temporal relations of the local features for action recognition. First STIPs are extracted, then PWFs are constructed by grouping pairs of STIPs which are both close in space and close in time. We propose a combination of two codebooks for video representation. Experiments on two standard human action datasets: the KTH dataset and the Weizmann dataset show that the proposed approach outperforms most existing methods.
- c15
-
Anh-Phong Ta,
Christian Wolf,
Guillaume Lavoué and
Atilla Baskurt
Recognizing and localizing individual activities through graph matching,
in the Proceedings of the International Conference on Advanced Video and Signal-Based Surveillance, 2010 (IEEE),
,oral presentation, 22.5% acceptance rate; Best Paper for track 'recognition', 5% acceptance rate.
In this paper we tackle the problem of detecting individual human actions in video sequences. While the most successful methods are based on local features, which proved that they can deal with changes in background, scale and illumination, most existing methods have two main shortcomings: first, they are mainly based on the individual power of spatio-temporal interest points (STIP), and therefore ignore the spatio-temporal relationships between them. Second, these methods mainly focus on direct classification techniques to classify the human activities, as opposed to detection and localization. In order to overcome these limitations, we propose a new approach, which is based on a graph matching algorithm for activity recognition. In contrast to most previous methods which classify entire video sequences, we design a video matching method from two sets of ST-points for human activity recognition. First, points are extracted, and a hyper graphs are constructed from them, i.e. graphs with edges involving more than 2 nodes (3 in our case). The activity recognition problem is then transformed into a problem of finding instances of model graphs in the scene graph. By matching local features instead of classifying entire sequences, our method is able to detect multiple different activities which occur simultaneously in a video sequence. Experiments on two standard datasets demonstrate that our method is comparable to the existing techniques on classification, and that it can, additionally, detect and localize activities.
- c14
-
Pierre-Yves Laffont, Jong-Yun Jun,
Christian Wolf,
Yu-Wing Tai,
Khalid Idrissi,
George Drettakis, Sung-Eui Yoon,
Interactive Content-Aware Zooming,
In Graphics Interface, 2010.
We propose a novel, interactive content-aware zooming operator that allows effective and efficient visualization of high resolution images on small screens, which may have different aspect ratios compared to the input images. Our approach applies an image retargeting method in order to fit an entire image into the limited screen space. This can provide global, but approximate views for lower zoom levels. However, as we zoom more closely into the image, we continuously unroll the distortion to provide local, but more detailed and accurate views for higher zoom levels. In addition, we propose to use an adaptive view-dependent mesh to achieve high retargeting quality, while maintaining interactive performance. We demonstrate the effectiveness of the proposed operator by comparing it against the traditional zooming approach, and a method stemming from a direct combination of existing works.
- c13
-
Moez Baccouche,
Frank Mamalet
Christian Wolf,
Christophe Garcia,
Atilla Baskurt
Action Classifcation in Soccer Videos with Long Short-Term Memory Recurrent Neural Networks
In International Conference on Artificial Neural Networks (ICANN), 2010.
In this paper, we propose a novel approach for action classification in soccer videos using a recurrent neural network scheme. Thereby, we extract from each video action at each timestep a set of features which describe both the visual content (by the mean of a BoW approach) and the dominant motion (with a key point based approach). A Long Short-Term Memory-based Recurrent Neural Network is then trained to classify each video sequence considering the temporal evolution of the features for each timestep. Experimental results on the MICC-Soccer-Actions-4 database show that the proposed approach outperforms classification methods of related works (with a classification rate of 77 %), and that the combination of the two features (BoW and dominant motion) leads to a classification rate of 92 %.
- c12
-
Anh-Phong Ta,
Christian Wolf,
Guillaume Lavoué,
Atilla Baskurt
3D Object detection and viewpoint selection in sketch images using local patch-based Zernike moments,
in the Proceedings of the IEEE Workshop on Content Based Multimedia Indexing, pp. 189-194, 2009.
In this paper we present a new approach to detect and recognize 3D models in 2D storyboards which have been drawn during the production process of animated cartoons. Our method is robust to occlusion, scale and rotation. The lack of texture and color makes it difficult to extract local features of the target object from the sketched storyboard. Therefore the existing approaches using local descriptors like interest points can fail in such images. We propose a new framework which combines patch-based Zernike descriptors with a method enforcing spatial constraints for exactly detecting 3D models represented as a set of 2D views in the storyboards. Experimental results show that the proposed method can deal with partial object occlusion and is suitable for poorly textured objects.
- c11
-
Marc Mouret,
Christine Solnon,
Christian Wolf
Classification of images based on Hidden Markov Models,
in the Proceedings of the IEEE Workshop on Content Based Multimedia Indexing, pp. 169-174, 2009.
We propose to use hidden Markov models (HMMs) to classify images. Images are modeled by extracting symbols corresponding to 3x3 binary neighborhoods of interest points, and by ordering these symbols by decreasing saliency order, thus obtaining strings of symbols. HMMs are learned from sets of strings modeling classes of images. The method has been tested on the SIMPLIcity database and shows an improvement over competing approaches based on interest points. We also evaluate these approaches for classifying thumbnail images, i.e., low resolution images.
- c10
-
Vincent Vidal,
Christian Wolf,
Florent Dupont,
Guillaume Lavoué
Global triangular mesh regularization using conditional Markov random fields.
Poster (refereed, but not published: acceptance rate ~35%) at Symposium on Geometry Processing, 2009
We present a global mesh optimization framework based on a Conditional Markov Random Fied (CMRF or CRF) model suited for 3D triangular meshes of arbitrary topology. The remeshing task is formulated as a Bayesian estimation problem including data attached terms measuring the fidelity to the original mesh as well as a prior favoring high quality triangles. Since the best solution for vertex relocation is strongly related to the mesh connectivity, our approach iteratively modifies the mesh structure (connectivity plus vertex addition/removal) as well as the vertex positions, which are moved according to a well-defined energy function resulting from the CMRF model. Good solutions for the proposed model are obtained by a discrete graph cut algorithm examining global combinations of local candidates. Results on various 3D meshes compare favorably to recent state-of-the-art algorithms regarding the trade-off between triangle shape improvement and surface fidelity. Applications of this work mainly consist in regularizing meshes for numerical simulations and for improving mesh rendering.
- c9
-
Christian Wolf
Families of Markov models for document image segmentation,
In IEEE Machine Learning for Signal Processing Workshop, 2009
In this paper we compare several directed and undirected graphical models for different image segmentation problems in the domain of document image processing and analysis. We show that adapting the structure of the model to specific sitations at hand, for instance character restoration, recto/verso separation and segmenting high resolution character images, can significantly improve segmentation performance. We propose inference algorithms for the different models and we test them on different data sets.
- c8
-
Christian Wolf,
Improving recto document side restoration with an estimation of the verso side from a single scanned page
In the Proceedings of the IEEE International Conference on Pattern Recognition, pp. 1-4, 2008.
We present a new method for blind document bleed through removal based on separately restoring the recto and the verso side. The segmentation algorithm is based on separate Markov random fields (MRF) which results in a better adaptation of the prior to the content creation process (e.g. superimposing two pages), and the improvement of the estimation of the verso pixels through an estimation of the verso pixels covered by recto pixels. The labels of the initial recto and verso clusters are recognized without using any color or gray value information. The proposed method is evaluated empirically as well as through OCR improvement.
- c7
-
Guillaume Lavoué and Christian Wolf
,
Markov Random Fields for Improving 3D Mesh Analysis and Segmentation,
In the Proceedings of the Eurographics 2008 Workshop on 3D Object Retrieval.
Abstract
Mesh analysis and clustering have became important issues in order to improve the efficiency of common processing
operations like compression, watermarking or simplification. In this context we present a new method for
clustering / labeling a 3D mesh given any field of scalar values associated with its vertices (curvature, density,
roughness etc.). Our algorithm is based on Markov Random Fields, graphical probabilistic models. This Bayesian
framework allows (1) to integrate both the attributes and the geometry in the clustering, and (2) to obtain an optimal
global solution using only local interactions, du to the Markov property of the random field. We have defined
new observation and prior models for 3D meshes, adapted from image processing which achieve very good results
in terms of spatial coherency of the labeling. All model parameters are estimated, resulting in a fully automatic
process (the only required parameter is the number of clusters) which works in reasonable time (several seconds).
- c5
-
Graham W.
Taylor and Christian Wolf
Reinforcement Learning for Parameter Control of Text Detection in Images
and Video Sequences
Proceedings of the IEEE International Conference
on Information & Communication Technologies
,
2004.
6 pages.
A framework for parameterization in computer vision algorithms is evaluated by
optimizing ten parameters of the text detection for semantic indexing algorithm
preposed by Wolf et al. The Fuzzy ARTMAP neural network is used for generalization,
offering much faster learning than in a previous tabular implementation.
Difficulties in using a continuous action space are overcome by employing the DIRECT
method for global optimization without derivatives. The chosen parameters are
evaluated using metrics of recall and precision, and are shown to be superior to the
parameters previously recommended.
- c4
-
Christian Wolf ,
Jean-Michel Jolion and Francoise Chassaing.
Text Localization, Enhancement and Binarization in Multimedia Documents
Proceedings of the International Conference on Pattern Recognition (ICPR),
volume 4, pages 1037-1040, IEEE Computer Society.
August 11th-15th, 2002, Quebec City, Canada. 4 pages.
The systems currently available for content based image and video retrieval work
without semantic knowledge, i.e. they use image processing methods to extract low
level features of the data. The similarity obtained by these ap-proaches does not
always correspond to the similarity a human user would expect. A way to include more
semantic knowledge into the indexing process is to use the text
included in the images and video sequences. It is rich in information but easy to
use, e.g. by key word based queries. In this paper we present an algorithm to
localize artificial text in images and videos using a measure of accumulated
gradients and morphological post processing to detect the text. The quality of the
localized text is improved by robust multiple frame integration. A new technique for
the bina-rization of the text boxes is proposed. Finally, detection and OCR results
for a commercial OCR are presented.
@InProceedings{WolfICPR2002V,
Author = {C. Wolf and J.-M. Jolion and F. Chassaing},
Title = {Text {L}ocalization, {E}nhancement and {B}inarization in {M}ultimedia {D}ocuments},
BookTitle = {Proceedings of the {I}nternational {C}onference on {P}attern {R}ecognition},
Volume = {2},
Pages = {1037-1040},
year = 2002,
}
- c3
-
Christian Wolf and
David Doermann
Binarization of Low Quality Text using a Markov Random Field Model.
Proceedings of the International Conference on Pattern Recognition (ICPR),
volume 2, pages 160-163, IEEE Computer Society. August 11th-15th, 2002,
Quebec City, Canada. 4 pages.
Binarization techniques have been developed in the document analysis community for
over 30 years and many algorithms have been used successfully. On the other hand,
document analysis tasks are more and more frequently being applied to multimedia
documents such as video sequences. Due to low resolution and lossy compression, the
binarization of text included in the frames is a non trivial task. Existing
techniques work without a model of the spatial relationships in the image, which
makes them less powerful. We introduce a new technique based on a Markov Random
Field (MRF) model of the document. The model parameters (clique potentials) are
learned from training data and the binary image is estimated in a Bayesian
framework. The performance is evaluated using commercial OCR software.
@InProceedings{WolfICPR2002M,
Author = {C. Wolf and D. Doermann},
Title = {Binarization of {L}ow {Q}uality {T}ext using a {M}arkov {R}andom {F}ield {M}odel},
BookTitle = {Proceedings of the {I}nternational {C}onference on {P}attern {R}ecognition},
Volume = {3},
Pages = {160-163},
year = 2002,
}
- c1
-
Christian Wolf ,
Jean-Michel Jolion ,
Walter Kropatsch , and
Horst Bischof .
Content based Image Retrieval using Interest Points and Texture Features,
Proceedings of the International Conference on Pattern Recognition (ICPR),
volume 4, pages 234-237. IEEE Computer Society. September 3rd,
2000, Barcelona,
Spain. 4 pages.
Interest point detectors are used in computer vision to detect image points with
special properties, which can be geometric (corners) or non-geometric (contrast
etc.). Gabor functions and Gabor filters are regarded as excellent tools for
feature extraction and texture segmentation. This article presents methods how to
combine these methods for content based image retrieval and to generate a textural
description of images. Special emphasis is devoted to distance measure texture
descriptions. Experimental results of a query system are given.
This work was supported in part by the Austrian Science Foundation (FWF) under grant
S-7002-MAT.
@InProceedings{WolfICPR2000,
Author = {C. Wolf and J.M. Jolion and W. Kropatsch and H. Bischof},
Title = {Content {B}ased {I}mage {R}etrieval using {I}nterest {P}oints and {T}exture {F}eatures},
BookTitle = {Proceedings of the {I}nternational {C}onference on {P}attern {R}ecognition},
Volume = {4},
Pages = {234-237},
year = 2000,
}
-
Taygun Kekec,
Rémi Emonet,
Elisa Fromont,
Alain Trémeau and
Christian Wolf,
Contextually Constrained Deep Networks for Scene Labeling.
In Conférence d'Apprentissage Automatique,
2014.
Learning using deep learning architectures is a difficult problem: the complexity of the network and the gradient descent method used to update the network’s weights can both lead to overfitting phenomena and bad local optima. To overcome these problems in the context of full scene labeling, we would like to constraint parts of the network using some semantic context to 1) control its capacity while still allowing complex functions to be learned 2) obtain more meaningful layers which will avoid bad local optima. We first propose to learn a weak convolutional network which would provide us rough label maps over the neighborhood of a pixel. Then, we incorporate this weak learner in a bigger network previously trained using some label information on the neighborhood of a pixel. This iterative augmentation process aims at increasing the interpretability by constraining some features maps to learn precise contextual information. We show how this contextual knowledge yields higher accuracy than state-of- the-art architectures for Stanford and SIFT Flow scene labeling datasets. The approach is generic and can be applied to similar networks where contextual cues are available at training time.
-
Alaeddine Mihoub,
Gerard Bailly and
Christian Wolf,
Modeling sensory-motor behaviors for social robots.
In Workshop Affect, Compagnon Artificiel, Interaction, Rouen,
2014.
Modeling multimodal perception-action loops in face-to-face interactions is a crucial step in the process of building sensory-motor behaviors for social robots or users-aware Embodied Conversational Agents (ECA). In this paper, we compare trainable behavioral models based on sequential models (HMMs) and classifiers (SVMs and Decision Trees) inherently inappropriate to model sequential aspects. These models aim at giving pertinent perception/action skills for robots in order to generate optimal actions given the perceived actions of others and joint goals. We applied these models to parallel speech and gaze data collected from interacting dyads. The challenge was to predict the gaze of one subject given the gaze of the interlocutor and the voice activity of both. We show that Incremental Discrete HMM (IDHMM) generally outperforms classifiers and that injecting input context in the modeling process significantly improves the performances of all algorithms.
-
Oya Celiktutan,
Christian Wolf and
Bülent Sankur,
Appariement de points spatio-temporels par hyper-graphes et optimisation discrète exacte.
In "COmpression et REprésentation des Signaux Audiovisuels" (CORESA),
2012, 6 pages.
Les graphes et les hyper-graphes sont souvent utilisés pour la reconnaissance de modèles complexes et non-rigides en vision par ordinateur, soit par appariement de graphes ou par appariement de nuages de points par graphes. La plupart des formulations recourent à la minimisation d'une fonction d'énergie difficile contenant des termes géométriques ou structurels, souvent couplés avec des termes d'attache aux données comportant des informations liées à l'apparence locale. Les méthodes traditionnelles tente une résolution approximative du problème de minimisation, par exemple avec des techniques spectrales. Dans cet article nous traitons des données embarquées dans l'"espace-temps", comme cela est typiquement le cas pour les applications de reconnaissance d'actions. Nous montrons que, dans ce contexte, nous pouvons profiter des propriétés particulières du domaine temporel, notamment la causalité et l'ordre stricte imposé par cette dimension. Nous montrons que la complexité du problème est inférieure à la complexité de la problématique générale et nous dérivons un algorithme calculant la solution exacte. Comme une seconde contribution, nous proposons une nouvelle structure graphique allongée dans le temps. Nous soutenons que, au lieu résoudre le problème d'origine de manière approximative, une meilleure solution peut être obtenue par en résolvant, de manière exacte, un problème approché. Un algorithme de minimisation exacte est dérivé de cette structure et appliqué avec succès à la reconnaissance d'actions dans les vidéos.
-
Mingyuan Jiu,
Christian Wolf,
Christophe Garcia and
Atilla Baskurt
Supervised learning and codebook optimization with neural network,
"COmpression et REprésentation des Signaux Audiovisuels" (CORESA),
2012, 6 pages.
In this paper, we present a novel approach for supervised codebook learning and optimization with neural networks for bag of words models in visual recognition tasks. We propose a new supervised framework for joint codebook creation and class learning, which learns the codewords in a goal-directed way using the class labels of the training set. As a result, the codebook becomes more discriminative. Two different learning algorithms, one based on error backpropagation and one based on cluster label reassignment, are presented. We evaluate them on the KTH dataset for human action recognition, reporting very promising results. The proposed technique allows to improve the discriminative power of an unsupervised learned codebook, or to keep the discriminative power while decreasing the size of the learned codebook.
-
Moez Baccouche,
Frank Mamalet
Christian Wolf,
Christophe Garcia,
Atilla Baskurt
Une approche neuronale pour la classification d'actions de sport par la prise en compte du contenu visuel et du mouvement dominant
CORESA 2010, "COmpression et REprésentation des Signaux Audiovisuels",
2010, 6 pages.
Dans cet article, nous proposons une approche de classification automatique de séquences vidéo d’actions de sport. Pour cela, nous extrayons de chaque action des caractéristiques du contenu visuel, en utilisant deux approches, l’une par sac de mots, et l’autre par le mouvement dominant de la scène à chaque instant. La classification de l’évolution temporelle de ces caractéristiques extraites est gérée dynamiquement par un modèle neuronal, basé sur les réseaux de neurones récurrents à large « mémoire court-terme» (LSTM). Les expérimentations faites sur la base « MICCSoccer-Actions-4 » montrent que l’approche neuronale de classification permet d’obtenir des résultats supérieurs à l’état de l’art (76 % de bonne classification), et que la combinaison des caractéristiques (information visuelle et mouvement dominant) permet un taux de bonne classification de 92 %.
-
Christian Wolf
Séparation recto/verso d'un document par modélisation markovienne à double couche
CORESA 2009, "COmpression et REprésentation des Signaux Audiovisuels",
Toulouse, 2009, 6 pages.
Nous proposons un modèle markovien à deux couches pour la séparation des deux faces d'un document, dont une seule face a été numérisé. A l'aide de deux champs de Markov séparés, un pour chaque face, chaque pixel est modélisé par deux variables cachées connectées par une unique variable observée. L'avantage de cette formulation est une meilleure adaptation au processus ayant créé l'image observée (la superposition de deux pages indépendantes) ainsi que l'amélioration de la restauration, ç.à .d. de l'estimation des pixels recto, par une estimation des pixels verso couverts par ce derniers. L'inférence des variables cachées est réalisée par un algorithme itératif à base de coupure minimale dans un graphe étendant l'algorithme d'éxpansion alpha. Les résultats sont évalués à la fois de faç on empirique ainsi que par l'amélioration d'un résultat de reconnaissance OCR.
-
Christian Wolf and Gérald Gavin
,
Inference and parameter estimation on belief networks for image segmentation
Journées francophones des réseaux bayésiens, Lyon (France), May 2008
.
We introduce a new causal hierarchical belief network for image segmentation. Contrary
to classical tree structured (or pyramidal) models, the factor graph of the network contains
cycles. Each level of the hierarchical structure features the same number of sites as the base
level and each site on a given level has several neighbors on the parent level. Compared to
tree structured models, the (spatial) random process on the base level of the model is stationary
which avoids known drawbacks, namely visual artifacts in the segmented image. We propose
different parametrisations of the conditional probability distributions governing the transitions
between the image levels. A parametric distribution depending on a single parameter allows
the design of a fast inference algorithm on graph cuts, whereas the parameter is estimated with
a least squares technique. For arbitrary distributions, we propose inference with loopy belief
propagation and we introduce a new parameter estimation technique adapted to the model.
-
Remi Landais, Christian Wolf,
Laurent Vinet and
Jean-Michel Jolion.
Utilisation de connaissances a priori pour le paramétrage d'un
algorithme de
détection de textes dans les documents audiovisuels. Appliation
à un corpus de journaux télévisés.
14ème Congrés Francophone de Reconnaissance des Formes
et Intelligence Artificielle.
2004, 10 pages.
-
Christian Wolf and
Jean-Michel Jolion.
Détection de textes de scenes dans des images issues d'un flux
vidéo,
CORESA 2003, "COmpression et REprésentation des Signaux Audiovisuels",
pages 63-66. January 16th - 17th 2003, Lyon. 4 pages.
La plupart des travaux sur la détection de texte se concentre sur le texte
artificiel et horizontal. Nous proposons une méthode de détection en orientation
générale qui repose sur un filtre directionnel appliqué dans plusieurs orientations.
Un algorithme de relaxation hiérarchique est employé pour consolider les résultats
locaux de direction. Une étape de vote entre des directions permet d'obtenir une
image binaire localisant les zones de textes.
-
Christian Wolf and
Jean-Michel Jolion.
Vidéo OCR - Détection et extraction du texte.
Colloque International Francophone sur l´Ecrit et le Document,
pages 215-224. Hammamet-Tunesie, 20-23 octobre 2002.
Les systémes d'indexation ou de recherche par le contenu disponibles actuellement
travaillent sans connaissance (systémes pré-attentifs). Malheureusement les requétes
construites ne correspondent pas toujours aux résultats obtenus par un humain qui
interpréte le contenu du document. Le texte présent dans les vidéos représente une
caractéristique é la fois riche en information et cependant simple, cela permet de
compléter les requétes classiques par des mots clefs.
Nous présentons dans cet article un projet visant é la détection et la
reconnaissance du texte présent dans des images ou des séquences vidéo. Nous
proposons un schéma de détection s'appuyant sur la mesure du gradient directionnel
cumulé. Dans le cas des séquences vidéo, nous introduisons un processus de
fiabilisation des détections et l'amélioration des textes détectés par un suivi et
une intégration temporelle.
-
Christian Wolf and
Jean-Michel Jolion.
Extraction de texte dans des videos: le cas de la binarisation,
Congrés Francophone de Reconnaissance des Formes
et Intelligence Artificielle,
volume 1, pages 145-152, January 8th-10th 2002, Angers.
Dans cet article nous abordons la probléme de la binarisation de "boites", i.e.
sous-image, contenant du texte. Nous montrons que la spécificité des contenus vidéos
améne é la conception d'une nouvelle approche de cette étape de binarisation en
regard des techniques habituelles tant du traitement d'image au sens large, que du
domaine de l'analyse de documents écrits.
We present in this paper some researches on thresholding of "text boxes"
(sub-images containing artificial texts and extracted from videos). We show that the
particular context of videos leads to the formalization of a new approach of this
step regarding the usual and wellknow techniques used in image analysis and more
particularly for segmentation of written documents.
-
Christian Wolf ,
Jean-Michel Jolion and
Francoise Chassaing.
Vidéo OCR - Détection et extraction du texte,
CORESA 2001, 7ème Journées d´Études
et d´Echanges "COmpression et REprésentation des Signaux
Audiovisuels",
pages 251-258, November 12th - 13th 2001, Dijon.
Les systémes d'indexation ou de recherche par le contenu disponibles actuellement
travaillent sans connaissance (systémes pré-attentifs). Malheureusement les requétes
construites ne correspondent pas toujours aux résultats obtenus par un humain qui
interpréte le contenu du document. Le texte présent dans les vidéos représente une
caractéristique é la fois riche en information et cependant simple, cela permet de
compléter les requétes classiques par des mots clefs. Nous présentons dans cet
article un projet visant é la détection et la reconnaissance du texte présent dans
des images ou des séquences vidéo. Nous proposons un schéma de détection s'appuyant
sur la mesure du gradient directionnel cumulé. Dans le cas des séquences vidéo, nous
introduisons un processus de fiabilisation des détections et l'amélioration des
textes détectés par un suivi et une intégration temporelle.
-
Christian Wolf and
Jean-Michel Jolion .
Vidéo OCR - Détection et extraction du texte,
ORASIS 2001, Congrès francophone de vision,
5-8 Juin 2001, pages 415-424, IRIT, route de Narbonne, 31062, Toulouse
Cedex 4, France.
Nous présentons dans cet article les premiéres étapes d'un projet visant é la
détection et la reconnaissance du texte présent dans des images ou des séquences
vidéo. Nous insisterons ici sur la caractérisation de ce type de texte en regard des
textes présents dans le documents classiques. Nous proposons un schéma de détection
s'appuyant sur la mesure du gradient diréctionnel cumulé. Dans le cas des séquences,
nous introduisons un processus de fiabilisation des détections et l'amélioration des
textes détectés par un suivi et une intégration temporelle.
-
Christian Wolf ,
Jean-Michel Jolion , and
Horst Bischof.
Histograms for Texture based Image Retrieval,
Proceedings of the OEAGM,
Robert Sablatnig and Christian Menard (Ed.), pages 169-176. Oldenbourg, 25th
May 2000. 8 pages.
Interest point detectors are used in computer vision to detect image points with
special properties, which can be geometric (corners) or non-geometric (contrast
etc.). Gabor functions and Gabor filters are regarded as excellent tools for feature
extraction and texture segmentation. This article presents methods how to combine
these methods for content based image retrieval and to generate a textural
description of images. Special emphasis is devoted to distance measure texture
descriptions. Experimental results of a query system are given.


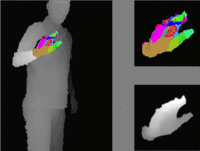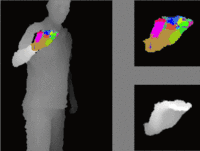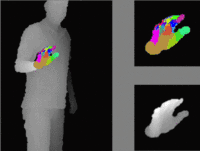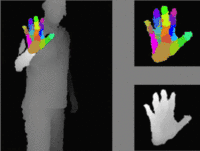{kind=link}