 arxiv pre-print.
arxiv pre-print.
arxiv pre-print.
arxiv pre-print.
Transformers are AI's workhorse with strong performance in modeling sequential data, but their computational cost becomes prohibitive when processing long sequences. We target long-horizon streaming vision and robotics applications like map-free pose estimation, where it is particularly impractical to store and maintain a history of observations. Recurrent Transformers address this limitation by maintaining fixed-size memory but their performance lags behind that of transformers operating over the full observation history. We argue that this gap does not stem from architectural limitations, but from differences in how these models learn to compress past information. Without access to an observation history, recurrent models must explicitly decide what to retain in memory at each step, a significantly harder learning problem. In this work, we propose a distillation approach that transfers the compression strategy of a classical full-history transformer to a recurrent variant. We enable this by designing a teacher model that explicitly compresses its observation history into a fixed-size bottleneck representation. By directly supervising the student's memory with this bottleneck representation, we align the two compression mechanisms. We show that this approach allows to train a recurrent latent robotic memory with linear-time complexity while substantially narrowing the performance gap to full-history transformers.
Trained policies for real-world robotics, be they end-to-end trained or integrated with VLMs to form VLAs, require computer vision components in the form of pre-trained visual encoders, ViTs. These encoders are an essential component and it has been shown that their power does not emerge from training on robotics downstream losses alone. Pre-training with auxiliary losses in the form of computer-vision pre-text tasks is a defining factor and heavily conditions agent performance in robotics tasks. In this unprecedented large-scale study we ran 966 navigation episodes with a fast-moving robot in a real-world building for 24km and asked which components really matter for the computer vision aspects of robotics: we evaluate state-of-the art visual encoders, including known general computer-vision work horses, in realistic conditions. We explore the usefulness of heterogeneous multi-teacher distillation leading to encoders with multiple different and complementary skills. We investigate how much information from these encoders is necessary for robotics by bottlenecking them in a principled and ``spatially useful'' way and we show that this leads to the emergence of interpretable features linked to affordances. We also argue that training policies on RGB data alone does not lead to an optimal usage of visual features and show this by finetuning policies pre-trained on privileged information. All in all, we paint a more complete picture of what aspects of computer vision are relevant for real-world navigation.
Image goal navigation requires two different skills: firstly, core navigation skills, including the detection of free space and obstacles, and taking decisions based on an internal representation; and secondly, computing directional information by comparing visual observations to the goal image. Current state-of-the-art methods either rely on dedicated image-matching, or pre-training of computer vision modules on relative pose estimation. In this paper, we study whether this task can be efficiently solved with end-to-end training of full agents with RL, as has been claimed by recent work. A positive answer would have impact beyond Embodied AI and allow training of relative pose estimation from reward for navigation alone. In a large study we investigate the effect of architectural choices like late fusion, channel stacking, space-to-depth projections and cross-attention, and their role in the emergence of relative pose estimators from navigation training. We show that the success of recent methods is influenced up to a certain extent by simulator settings, leading to shortcuts in simulation. However, we also show that these capabilities can be transferred to more realistic setting, up to some extend. We also find evidence for correlations between navigation performance and probed (emerging) relative pose estimation performance, an important sub skill.
Methods for navigation based on large-scale learning typically treat each episode as a new problem, where the agent is spawned with a clean memory in an unknown environment. While these generalization capabilities to an unknown environment are extremely important, we claim that, in a realistic setting, an agent should have the capacity of exploiting information collected during earlier robot operations. We address this by introducing a new retrieval-augmented agent, trained with RL, capable of querying a database collected from previous episodes in the same environment and learning how to integrate this additional context information. We introduce a unique agent architecture for the general navigation task, evaluated on ObjectNav, ImageNav and Instance-ImageNav. Our retrieval and context encoding methods are data-driven and heavily employ vision foundation models (FM) for both semantic and geometric understanding. We propose new benchmarks for these settings and we show that retrieval allows zero-shot transfer across tasks and environments while significantly improving performance.
One key aspect of spatially aware robots is the ability to "find their bearings", i.e. to correctly situate themselves in previously seen spaces. In this work, we focus on this particular scenario of continuous robotics operations, where information observed before an actual episode start is exploited to optimize efficiency. We introduce a new model, Kinaema, and agent, capable of integrating a stream of visual observations while moving in a potentially large scene, and upon request, processing a query image and predicting the relative position of the shown space with respect to its current position. Our model does not explicitly store an observation history, therefore does not have hard constraints on context length. It maintains an implicit latent memory, which is updated by a transformer in a recurrent way, compressing the history of sensor readings into a compact representation. We evaluate the impact of this model in a new downstream task we call "Mem-Nav". We show that our large-capacity recurrent model maintains a useful representation of the scene, navigates to goals observed before the actual episode start, and is computationally efficient, in particular compared to classical transformers with attention over an observation history.
Progress in Embodied AI has made it possible for end-to-end-trained agents to navigate in photo-realistic environments with high-level reasoning and zero-shot or language-conditioned behavior, but evaluations and benchmarks are still dominated by simulation. In this work, we focus on the fine-grained behavior of fast-moving real robots and present a large-scale experimental study involving 262 navigation episodes in a real environment with a physical robot, where we analyze the type of reasoning emerging from end-to-end training. In particular, we study the presence of realistic dynamics which the agent learned for open-loop forecasting, and their interplay with sensing. We analyze the way the agent uses latent memory to hold elements of the scene structure and information gathered during exploration. We probe the planning capabilities of the agent, and find in its memory evidence for somewhat precise plans over a limited horizon. Furthermore, we show in a post-hoc analysis that the value function learned by the agent relates to long-term planning. Put together, our experiments paint a new picture on how using tools from computer vision and sequential decision making have led to new capabilities in robotics and control.
Implicit representations such as Neural Radiance Fields (NeRF) have been shown to be very effective at novel view synthesis. However, these models typically require manual and careful human data collection for training. In this paper, we present AutoNeRF, a method to collect data required to train NeRFs using autonomous embodied agents. Our method allows an agent to explore an unseen environment efficiently and use the experience to build an implicit map representation autonomously. We compare the impact of different exploration strategies including handcrafted frontier-based exploration and modular approaches composed of trained high-level planners and classical low-level path followers. We train these models with different reward functions tailored to this problem and evaluate the quality of the learned representations on four different downstream tasks: classical viewpoint rendering, map reconstruction, planning, and pose refinement. Empirical results show that NeRFs can be trained on actively collected data using just a single episode of experience in an unseen environment, and can be used for several downstream robotic tasks, and that modular trained exploration models significantly outperform the classical baselines.
Successfully addressing a wide variety of tasks is a core ability of autonomous agents, which requires flexibly adapting the underlying decision-making strategies and, as we argue in this work, also adapting the underlying perception modules. An analogical argument would be the human visual system, which uses top-down signals to focus attention determined by the current task. Similarly, in this work, we adapt pre-trained large vision models conditioned on specific downstream tasks in the context of multi-task policy learning. We introduce task-conditioned adapters that do not require finetuning any pre-trained weights, combined with a single policy trained with behavior cloning and capable of addressing multiple tasks. We condition the policy and visual adapters on task embeddings, which can be selected at inference if the task is known, or alternatively inferred from a set of example demonstrations. To this end, we propose a new optimization-based estimator. We evaluate the method on a wide variety of tasks of the CortexBench benchmark and show that, compared to existing work, it can be addressed with a single policy. In particular, we demonstrate that adapting visual features is a key design choice and that the method generalizes to unseen tasks given visual demonstrations.
Modern techniques for physical simulations rely on numerical schemes and mesh-refinement methods to address trade-offs between precision and complexity, but these handcrafted solutions are tedious and require high computational power. Data-driven methods based on large-scale machine learning promise high adaptivity by integrating long-range dependencies more directly and efficiently. In this work, we focus on computational fluid dynamics and address the shortcomings of a large part of the literature, which are based on fixed support for computations and predictions in the form of regular or irregular grids. We propose a novel setup to perform predictions in a continuous spatial and temporal domain while being trained on sparse observations. We formulate the task as a double observation problem and propose a solution with two interlinked dynamical systems defined on, respectively, the sparse positions and the continuous domain, which allows to forecast and interpolate a solution from the initial condition. Our practical implementation involves recurrent GNNs and a spatio-temporal attention observer capable of interpolating the solution at arbitrary locations. Our model not only generalizes to new initial conditions (as standard auto-regressive models do) but also performs evaluation at arbitrary space and time locations. We evaluate on three standard datasets in fluid dynamics and compare to strong baselines, which are outperformed in classical settings and the extended new task requiring continuous predictions.
Agents navigating in 3D environments require some form of memory, which should hold a compact and actionable representation of the history of observations useful for decision taking and planning. In most end-to-end learning approaches the representation is latent and usually does not have a clearly defined interpretation, whereas classical robotics addresses this with scene reconstruction resulting in some form of map, usually estimated with geometry and sensor models and/or learning. In this work we propose to learn an actionable representation of the scene independently of the targeted downstream task and without explicitly optimizing reconstruction. The learned representation is optimized by a blind auxiliary agent trained to navigate with it on multiple short sub episodes branching out from a waypoint and, most importantly, without any direct visual observation. We argue and show that the blindness property is important and forces the (trained) latent representation to be the only means for planning. With probing experiments we show that the learned representation optimizes navigability and not reconstruction. On downstream tasks we show that it is robust to changes in distribution, in particular the sim2real gap, which we evaluate with a real physical robot in a real office building, significantly improving performance.
Bird's-eye view (BEV) maps are an important geometrically structured representation widely used in robotics, in particular self-driving vehicles and terrestrial robots. Existing algorithms either require depth information for the geometric projection, which is not always reliably available, or are trained end-to-end in a fully supervised way to map visual first-person observations to BEV representation, and are therefore restricted to the output modality they have been trained for. In contrast, we propose a new model capable of performing zero-shot projections of any modality available in a first person view to the corresponding BEV map. This is achieved by disentangling the geometric inverse perspective projection from the modality transformation, eg. RGB to occupancy. The method is general and we showcase experiments projecting to BEV three different modalities: semantic segmentation, motion vectors and object bounding boxes detected in first person. We experimentally show that the model outperforms competing methods, in particular the widely used baseline resorting to monocular depth estimation.
Understanding and mapping a new environment are core abilities of any autonomously navigating agent. While classical robotics usually estimates maps in a stand-alone manner with SLAM variants, which maintain a topological or metric representation, end-to-end learning of navigation keeps some form of memory in a neural network. Networks are typically imbued with inductive biases, which can range from vectorial representations to birds-eye metric tensors or topological structures. In this work, we propose to structure neural networks with two neural implicit representations, which are learned dynamically during each episode and map the content of the scene: (i) the Semantic Finder predicts the position of a previously seen queried object; (ii) the Occupancy and Exploration Implicit Representation encapsulates information about explored area and obstacles, and is queried with a novel global read mechanism which directly maps from function space to a usable embedding space. Both representations are leveraged by an agent trained with Reinforcement Learning (RL) and learned online during each episode. We evaluate the agent on Multi-Object Navigation and show the high impact of using neural implicit representations as a memory source.
Navigation of terrestrial robots is typically ad- dressed either with localization and mapping (SLAM) followed by classical planning on the dynamically created maps, or by machine learning (ML), often through end-to-end training with reinforcement learning (RL) or imitation learning (IL). Recently, modular designs have achieved promising results, and hybrid algorithms that combine ML with classical planning have been proposed. Existing methods implement these combi- nations with hand-crafted functions, which cannot fully exploit the complementary nature of the policies and the complex regularities between scene structure and planning performance. Our work builds on the hypothesis that the strengths and weaknesses of neural planners and classical planners follow some regularities, which can be learned from training data, in particular from interactions. This is grounded on the assumption that, both, trained planners and the mapping algorithms underlying classical planning are subject to failure cases depending on the semantics of the scene and that this dependence is learnable: for instance, certain areas, objects or scene structures can be reconstructed easier than others. We propose a hierarchical method composed of a high-level planner dynamically switching between a classical and a neural planner. We fully train all neural policies in simulation and evaluate the method in both simulation and real experiments with a LoCoBot robot, showing significant gains in performance, in particular in the real environment. We also qualitatively conjecture on the nature of data regularities exploited by the high-level planner.
Estimating fluid dynamics is classically done through the simulation and integration of numerical models solving the Navier-Stokes equations, which is computationally complex and time-consuming even on high-end hardware. This is a notoriously hard problem to solve, which has recently been addressed with machine learning, in particular graph neural networks (GNN) and variants trained and evaluated on datasets of static objects in static scenes with fixed geometry. We attempt to go beyond existing work in complexity and introduce a new model, method and benchmark. We propose EAGLE: a large-scale dataset of ∼1.1 million 2D meshes resulting from simulations of unsteady fluid dynamics caused by a moving flow source interacting with nonlinear scene structure of varying geometries, with 600 different scenes of three different types in total. To perform future forecasting of pressure and velocity on the challenging EAGLE dataset, we introduce a new mesh transformer. It leverages node clustering, graph pooling and global attention to learn long-range dependencies between spatially distant data points without needing a large number of iterations, as existing GNN methods do. We show that our transformer outperforms state-of-the-art performance on, both, existing synthetic and real datasets and on EAGLE. Finally, we highlight that our approach learns to attend to airflow, integrating complex information in a single iteration.
Navigation has been classically solved in robotics through the combination of SLAM and planning. More recently, beyond waypoint planning, problems involving significant components of (visual) high-level reasoning have been explored in simulated environments, mostly addressed with large-scale machine learning, in particular RL, offline-RL or imitation learning. These methods require the agent to learn various skills like local planning, mapping objects and querying the learned spatial representations. In contrast to simpler tasks like waypoint planning (PointGoal), for these more complex tasks the current state-of-the-art models have been thoroughly evaluated in simulation but, to our best knowledge, not yet in real environments. In this work we focus on sim2real transfer. We target the challenging Multi-Object Navigation (Multi-ON) task [41] and port it to a physical environment containing real replicas of the originally virtual Multi-ON objects. We introduce a hybrid navigation method, which decomposes the problem into two different skills: (1) waypoint navigation is addressed with classical SLAM combined with a symbolic planner, whereas (2) exploration, semantic mapping and goal retrieval are dealt with deep neural networks trained with a combination of supervised learning and RL. We show the advantages of this approach compared to end-to-end methods both in simulation and a real environment and outperform the SOTA for this task [28].

Cette soumission trace un historique des réseaux de neurones informatiques pour le traitement du signal et des images, depuis leurs fondements jusqu'aux succès du deep learning moderne. Nous présentons leurs éléments clés des modèles en termes d'architecture et d'entraînement, et soulignons l'importance du Big Data et de l'accélération matérielle des GPU. Enfin, nous mentionnons les tendances fortes actuelles à travers l'apprentissage auto-supervisé, les mécanismes attentionnels et les transformers.
Controlling UAV flights precisely requires a realistic dynamic model and accurate state estimates from onboard sensors like UAV, GPS and visual observations. Obtaining a precise dynamic model is extremely difficult, as important aerodynamic effects are hard to model, in particular ground effect and other turbulences. While machine learning has been used in the past to estimate UAV created turbulence, this was restricted to flat grounds or diffuse in-flight air turbulences, both without taking into account obstacles. In this work we address the complex problem of estimating in-flight turbulences caused by obstacles, in particular the complex structures in cluttered environments. We learn a mapping from control input and images captured by onboard cameras to turbulence. In a large-scale setting, we train a model over a large number of different simulated photo-realistic environments loaded into the this simulator augmented with a dynamic UAV model and an analytic ground effect model. We transfer the model from simulation to a real environment and evaluate on real UAV flights from the EuRoC-MAV dataset, showing that the model is capable of good sim2real generalization performance. The dataset will be made publicly available upon acceptance.
As in many tasks combining vision and language, both modalities play a crucial role in Visual Question Answering (VQA). To properly solve the task, a given model should both understand the content of the proposed image and the nature of the question. While the fusion between modalities, which is another obviously important part of the problem, has been highly studied, the vision part has received less attention in recent work. Current state-of-the-art methods for VQA mainly rely on off-the-shelf object detectors delivering a set of object bounding boxes and embeddings, which are then combined with question word embeddings through a reasoning module. In this paper, we propose an in-depth study of the vision-bottleneck in VQA, experimenting with both the quantity and quality of visual objects extracted from images. We also study the impact of two methods to incorporate the information about objects necessary for answering a question, in the reasoning module directly, and earlier in the object selection stage. This work highlights the importance of vision in the context of VQA, and the interest of tailoring vision methods used in VQA to the task at hand.
The emergence of data-driven approaches for control and planning in robotics have highlighted the need for developing experimental robotic platforms for data collection. However, their implementation is often complex and expensive, in particular for flying and terrestrial robots where the precise estimation of the position requires motion capture devices (MoCap) or Lidar. In order to simplify the use of a robotic platform dedicated to research on a wide range of indoor and outdoor environments, we present a data validation tool for ego-pose estimation that does not require any equipment other than the on-board camera. The method and tool allow a rapid, visual and quantitative evaluation of the quality of ego-pose sensors and are sensitive to different sources of flaws in the acquisition chain, ranging from desynchronization of the sensor flows to misevaluation of the geometric parameters of the robotic platform. Using computer vision, the information from the sensors is used to calculate the motion of a semantic scene point through its projection to the 2D image space of the on-board camera. The deviations of these keypoints from references created with a semi-automatic tool allow rapid and simple quality assessment of the data collected on the platform. To demonstrate the performance of our method, we evaluate it on two challenging standard UAV datasets as well as one dataset taken from a terrestrial robot.
The identification of a nonlinear dynamic model is an open topic in control theory, especially from sparse inputoutput measurements. A fundamental challenge of this problem is that very few to zero prior knowledge is available on both the state and the nonlinear system model. To cope with this challenge, we investigate the effectiveness of deep learning in the modeling of dynamic systems with nonlinear behavior by advocating an approach which relies on three main ingredients: (i) we show that under some structural conditions on the tobe-identified model, the state can be expressed in function of a sequence of the past inputs and outputs; (ii) this relation which we call the state map can be modelled by resorting to the welldocumented approximation power of deep neural networks; (iii) taking then advantage of existing learning schemes, a statespace model can be finally identified. After the formulation and analysis of the approach, we show its ability to identify three different nonlinear systems. The performances are evaluated in terms of open-loop prediction on test data generated in simulation as well as a real world data-set of unmanned aerial vehicle flight measurements.
In the context of visual navigation, the capacity to map a novel environment is necessary for an agent to exploit its observation history in the considered place and efficiently reach known goals. This ability can be associated with spatial reasoning, where an agent is able to perceive spatial relationships and regularities, and discover object affordances. In classical Reinforcement Learning (RL) setups, this capacity is learned from reward alone. We introduce supplementary supervision in the form of auxiliary tasks designed to favor the emergence of spatial perception capabilities in agents trained for a goal-reaching downstream objective. We show that learning to estimate metrics quantifying the spatial relationships between an agent at a given location and a goal to reach has a high positive impact in Multi-Object Navigation settings. Our method significantly improves the performance of different baseline agents, that either build an explicit or implicit representation of the environment, even matching the performance of incomparable oracle agents taking ground-truth maps as input.
Learning causal relationships in high-dimensional data (images, videos) is a hard task, as they are often defined on low dimensional manifolds and must be extracted from complex signals dominated by appearance, lighting, textures and also spurious correlations in the data. We present a method for learning counterfactual reasoning of physical processes in pixel space, which requires the prediction of the impact of interventions on initial conditions. Going beyond the identification of structural relationships, we deal with the challenging problem of forecasting raw video over long horizons. Our method does not require the knowledge or supervision of any ground truth positions or other object or scene properties. Our model learns and acts on a suitable hybrid latent representation based on a combination of dense features, sets of 2D keypoints and an additional latent vector per keypoint. We show that this better captures the dynamics of physical processes than purely dense or sparse representations. We introduce a new challenging and carefully designed counterfactual benchmark for predictions in pixel space and outperform strong baselines in physics-inspired ML and video prediction.
Visual navigation by mobile robots is classically tackled through SLAM plus optimal planning, and more recently through end-to-end training of policies implemented as deep networks. While the former are often limited to waypoint planning, but have proven their efficiency even on real physical environments, the latter solutions are most frequently employed in simulation, but have been shown to be able learn more complex visual reasoning, involving complex semantical regularities. Navigation by real robots in physical environments is still an open problem. End-to-end training approaches have been thoroughly tested in simulation only, with experiments involving real robots being restricted to rare performance evaluations in simplified laboratory conditions. In this work we present an in-depth study of the performance and reasoning capacities of real physical agents, trained in simulation and deployed to two different physical environments. Beyond benchmarking, we provide insights into the generalization capabilities of different agents training in different conditions. We visualize sensor usage and the importance of the different types of signals. We show, that for the PointGoal task, an agent pre-trained on wide variety of tasks and fine-tuned on a simulated version of the target environment can reach competitive performance without modelling any sim2real transfer, i.e. by deploying the trained agent directly from simulation to a real physical robot.
We address planning and navigation in challenging 3D video games featuring maps with disconnected regions reachable by agents using special actions. In this setting, classical symbolic planners are not applicable or diffi- cult to adapt. We introduce a hybrid technique combin- ing a low level policy trained with reinforcement learn- ing and a graph based high level classical planner. In addition to providing human-interpretable paths, the ap- proach improves the generalization performance of an end-to-end approach in unseen maps, where it achieves a 20% absolute increase in success rate over a recurrent end-to-end agent on a point to point navigation task in yet unseen large-scale maps of size 1km×1km. In an in- depth experimental study, we quantify the limitations of end-to-end Deep RL approaches in vast environments and we also introduce “GameRLand3D”, a new bench- mark and soon to be released environment built with the Unity engine able to generate complex procedural 3D maps for navigation tasks. An overview video is available here.
We present Godot Reinforcement Learning (RL) Agents, an open-source interface for developing environments and agents in the Godot Game Engine. The Godot RL Agents interface allows the design, creation and learning of agent behaviors in challenging 2D and 3D environments with various on-policy and off-policy Deep RL algorithms. We provide a standard Gym interface, with wrappers for learning in the Ray RLlib and Stable Baselines RL frameworks. This allows users access to over 20 state of the art on-policy, off-policy and multi-agent RL algorithms. The framework is a versatile tool that allows researchers and game designers the ability to create environments with discrete, continuous and mixed action spaces. The interface is relatively performant, with 12k interactions per second on a high end laptop computer, when parallized on 4 CPU cores. An overview video is available here.
We address the problem of universal domain adaptation (UDA) in ordinal regression (OR), which attempts to solve classification problems in which labels are not independent, but follow a natural order. We show that the UDA techniques developed for classification and based on the clustering assumption, under-perform in OR settings. We propose a method that complements the OR classifier with an auxiliary task of order learning, which plays the double role of discriminating between common and private instances, and expanding class labels to the private target images via ranking. Combined with adversarial domain discrimination, our model is able to address the closed set, partial and open set configurations. We evaluate our method on three face age estimation datasets, and show that it outperforms the baseline methods.
Visual Question Answering systems target answering open-ended textual questions given input images. They are a testbed for learning high-level reasoning with a primary use in HCI, for instance assistance for the visually impaired. Recent research has shown that state-of-the-art models tend to produce answers exploiting biases and shortcuts in the training data, and sometimes do not even look at the input image, instead of performing the required reasoning steps. We present VisQA, a visual analytics tool that explores this question of reasoning vs. bias exploitation. It exposes the key element of state-of-the-art neural models -- attention maps in transformers. Our working hypothesis is that reasoning steps leading to model predictions are observable from attention distributions, which are particularly useful for visualization. The design process of VisQA was motivated by well-known bias examples from the fields of deep learning and vision-language reasoning and evaluated in two ways. First, as a result of a collaboration of three fields, machine learning, vision and language reasoning, and data analytics, the work lead to a direct impact on the design and training of a neural model for VQA, improving model performance as a consequence. Second, we also report on the design of VisQA, and a goal-oriented evaluation of VisQA targeting the analysis of a model decision process from multiple experts, providing evidence that it makes the inner workings of models accessible to users.
Methods for Visual Question Anwering (VQA) are notorious for leveraging dataset biases rather than performing reasoning, hindering generalization. It has been recently shown that better reasoning patterns emerge in attention layers of a state-of-the-art VQA model when they are trained on perfect (oracle) visual inputs. This provides evidence that deep neural networks can learn to reason when training conditions are favorable enough. However, transferring this learned knowledge to deployable models is a challenge, as much of it is lost during the transfer. We propose a method for knowledge transfer based on a regularization term in our loss function, supervising the sequence of required reasoning operations. We provide a theoretical analysis based on PAC-learning, showing that such program prediction can lead to decreased sample complexity under mild hypotheses. We also demonstrate the effectiveness of this approach experimentally on the GQA dataset and show its complementarity to BERT-like self-supervised pre-training.
The Robotics community has started to heavily rely on increasingly realistic 3D simulators for large-scale training of robots on massive amounts of data. But once robots are deployed in the real world, the simulation gap, as well as changes in the real world (e.g. lights, objects displacements) lead to errors. In this paper, we introduce Sim2RealViz, a visual analytics tool to assist experts in understanding and reducing this gap for robot ego-pose estimation tasks, i.e. the estimation of a robot's position using trained models. Sim2RealViz displays details of a given model and the performance of its instances in both simulation and real-world. Experts can identify environment differences that impact model predictions at a given location and explore through direct interactions with the model hypothesis to fix it. We detail the design of the tool, and case studies related to the exploit of the regression to the mean bias and how it can be addressed, and how models are perturbed by the vanish of landmarks such as bikes.
We address the problem of output prediction, ie. designing a model for autonomous nonlinear systems capable of forecasting their future observations. We first define a general framework bringing together the necessary properties for the development of such an output predictor. In particular, we look at this problem from two different viewpoints, control theory and data-driven techniques (machine learning), and try to formulate it in a consistent way, reducing the gap between the two fields. Building on this formulation and problem definition, we propose a predictor structure based on the Kazantzis-Kravaris/Luenberger (KKL) observer and we show that KKL fits well into our general framework. Finally, we propose a constructive solution for this predictor that solely relies on a small set of trajectories measured from the system. Our experiments show that our solution allows to obtain an efficient predictor over a subset of the observation space.
Since its inception, Visual Question Answering (VQA) is notoriously known as a task, where models are prone to exploit biases in datasets to find shortcuts instead of performing high-level reasoning, required for generalization. Classical methods address these issues with different techniques including removing biases from training data, or adding branches to models to detect and remove biases. In this paper, we argue that uncertainty in vision is a dominating factor preventing the successful learning of reasoning in vision and language problems. We train a visual oracle with perfect sight, and in a large scale study provide experimental evidence that it is much less prone to exploiting spurious dataset biases compared to standard models. In particular, we propose to study the attention mechanisms at work in the visual oracle and compare them with a SOTA Transformer-based model. We provide an in-depth analysis and visualizations of reasoning patterns obtained with an online visualization tool which we make publicly available (https://reasoningpatterns.github.io). We exploit these insights by transferring reasoning patterns from the oracle model to a SOTA Transformer-based VQA model taking as input standard noisy inputs. Experiments show successful transfer as evidenced by higher overall accuracy, as well as accuracy on infrequent answers for each type of question, which provides evidence for improved generalization and a decrease of the dependency on dataset biases.
To be reliable on rare events is an important requirement for systems based on machine learning. In this work we focus on Visual Question Answering (VQA), where, in spite of recent efforts, datasets remain imbalanced, causing shortcomings of current models: tendencies to overly exploit dataset biases and struggles to generalise to unseen associations of concepts. We focus on a systemic evaluation of model error distributions and address fundamental questions: How is the prediction error distributed? What is the prediction accuracy on infrequent vs. frequent concepts? In this work, we design a new benchmark based on a fine-grained reorganization of the GQA dataset [1], which allows to precisely answer these questions. It introduces distributions shifts in both validation and test splits, which are defined on question groups and are thus tailored to each question. We performed a large-scale study and we experimentally demonstrate that several state-of-the-art VQA models, even those specifically designed for bias reduction, fail to address questions involving infrequent concepts. Furthermore, we show that the high accuracy obtained on the frequent concepts alone is mechanically increasing overall accuracy, covering up the true behavior of current VQA models.
In this paper we introduce a Transformer-based approach to video object segmentation (VOS). To address compounding error and scalability issues of prior work, we propose a scalable, end-to-end method for VOS called Sparse Spatiotemporal Transformers (SST). SST extracts per-pixel representations for each object in a video using sparse attention over spatiotemporal features. Our attention-based formulation for VOS allows a model to learn to attend over a history of multiple frames and provides suitable inductive bias for performing correspondence-like computations necessary for solving motion segmentation. We demonstrate the effectiveness of attention-based over recurrent networks in the spatiotemporal domain. Our method achieves competitive results on YouTube-VOS and DAVIS 2017 with improved scalability and robustness to occlusions compared with the state of the art.
Since its appearance, Visual Question Answering (VQA, i.e. answering a question posed over an image), has always been treated as a classification problem over a set of predefined answers. Despite its convenience, this classification approach poorly reflects the semantics of the problem limiting the answering to a choice between independent proposals, without taking into account the similarity between them (e.g. equally penalizing for answering \say{cat} or \say{German shepherd} instead of \say{dog}). We address this issue by proposing (1) two measures of proximity between VQA classes, and (2) a corresponding loss which takes into account the estimated proximity. This significantly improves the generalization of VQA models by reducing their language bias. In particular, we show that our approach is completely model-agnostic since it allows consistent improvements with three different VQA models. Finally, by combining our method with a language bias reduction approach, we report SOTA-level performance on the challenging VQAv2-CP dataset.
We present DRLViz, a visual analytics interface to interpret the internal memory of an agent (e.g. a robot) trained using deep reinforcement learning. This memory is composed of large temporal vectors updated when the agent moves in an environment and is not trivial to understand. It is often referred to as a black box as only inputs (images) and outputs (actions) are intelligible for humans. Using DRLViz, experts are assisted to interpret using memory reduction interactions, to investigate parts of the memory role when errors have been made, and ultimately to improve the agent training process. We report on several examples of use of DRLViz, in the context of video games simulators (ViZDoom) for a navigation scenario with item gathering tasks. We also report on experts evaluation using DRLViz, and applicability of DRLViz to other scenarios and navigation problems beyond simulation games, as well as its contribution to black box models interpret-ability and explain-ability in the field of visual analytics.
We train an agent to navigate in 3D environments using a hierarchical strategy including a high-level graph based planner and a local policy. Our main contribution is a data driven learning based approach for planning under uncertainty in topological maps, requiring an estimate of shortest paths in valued graphs with a probabilistic structure. Whereas classical symbolic algorithms achieve optimal results on noise-less topologies, or optimal results in a probabilistic sense on graphs with probabilistic structure, we aim to show that machine learning can overcome missing information in the graph by taking into account rich high-dimensional node features, for instance visual information available at each location of the map. Compared to purely learned neural white box algorithms, we structure our neural model with an inductive bias for dynamic programming based shortest path algorithms, and we show that a particular parameterization of our neural model corresponds to the Bellman-Ford algorithm. By performing an empirical analysis of our method in simulated photo-realistic 3D environments, we demonstrate that the inclusion of visual features in the learned neural planner outperforms classical symbolic solutions for graph based planning.
Tasks involving localization, memorization and planning in partially observable 3D environments are an ongoing challenge in Deep Reinforcement Learning. We present EgoMap, a spatially structured neural memory architecture. EgoMap augments a deep reinforcement learning agent's performance in 3D environments on challenging tasks with multi-step objectives. The EgoMap architecture incorporates several inductive biases including a differentiable inverse projection of CNN feature vectors onto a top-down spatially structured map. The map is updated with ego-motion measurements through a differentiable affine transform. We show this architecture outperforms both standard recurrent agents and state of the art agents with structured memory. We demonstrate that incorporating these inductive biases into an agent's architecture allows for stable training with reward alone, circumventing the expense of acquiring and labelling expert trajectories. A detailed ablation study demonstrates the impact of key aspects of the architecture and through extensive qualitative analysis, we show how the agent exploits its structured internal memory to achieve higher performance.
We consider the problem of supervised learning of a multi-model based controller for non-linear systems. Selected multiple linear controllers are used for different operating points and combined with a local weighting scheme, whose weights are predicted by a deep neural network trained online. The network uses process and model outputs to drive the controller towards a suitable mixture of operating points. The proposed approach, which combines machine learning and classical control of linear processes, allows efficient imple- mentation on complex industrial processes. In this work, the control problem consists in the design of a controller for a waste heat recovery system (WHRS) mounted on a heavy duty (HD) truck engine to decrease fuel consumption and meet the future pollutant emissions standard. Note that the contribution of this work is not specific to HD truck processes since it can be applied to any nonlinear system with an existing linear controller bank. The proposed control scheme is successfully evaluated on an Organic Rankine Cycle (ORC) process simulator and compared to a standard linear controller and to several strong multi-model baselines without learning.
Understanding causes and effects in mechanical systems is an essential component of reasoning in the physical world. This work poses a new problem of counterfactual learning of object mechanics from visual input. We develop the COPHY benchmark to assess the capacity of the state-of-the-art models for causal physical reasoning in a synthetic 3D environment and propose a model for learning the physical dynamics in a counterfactual setting. Having observed a mechanical experiment that involves, for example, a falling tower of blocks, a set of bouncing balls or colliding objects, we learn to predict how its outcome is affected by an arbitrary intervention on its initial conditions, such as displacing one of the objects in the scene. The alternative future is predicted given the altered past and a latent representation of the confounders learned by the model in an end-to-end fashion with no supervision. We compare against feedforward video prediction baselines and show how observing alternative experiences allows the network to capture latent physical properties of the environment, which results in significantly more accurate predictions at the level of super human performance.
The large adoption of the self-attention (i.e. transformer model) and BERT-like training principles has recently resulted in a number of high performing models on a large panoply of vision-and-language problems (such as Visual Question Answering (VQA), image retrieval, etc.). In this paper we claim that these State-Of-The-Art (SOTA) approaches perform reasonably well in structuring information inside a single modality but, despite their impressive performances , they tend to struggle to identify fine-grained inter-modality relationships. Indeed, such relations are frequently assumed to be implicitly learned during training from application-specific losses, mostly cross-entropy for classification. While most recent works provide inductive bias for inter-modality relationships via cross attention modules, in this work, we demonstrate (1) that the latter assumption does not hold, i.e. modality alignment does not necessarily emerge automatically, and (2) that adding weak supervision for alignment between visual objects and words improves the quality of the learned models on tasks requiring reasoning. In particular , we integrate an object-word alignment loss into SOTA vision-language reasoning models and evaluate it on two tasks VQA and Language-driven Comparison of Images. We show that the proposed fine-grained inter-modality supervision significantly improves performance on both tasks. In particular, this new learning signal allows obtaining SOTA-level performances on GQA dataset (VQA task) with pre-trained models without finetuning on the task, and a new SOTA on NLVR2 dataset (Language-driven Comparison of Images). Finally, we also illustrate the impact of the contribution on the models reasoning by visualizing attention distributions.
An important goal of research in Deep Reinforcement Learning in mobile robotics is to train agents capable of solving complex tasks, which require a high level of scene understanding and reasoning from an egocentric perspective. When trained from simulations, optimal environments should satisfy a currently unobtainable combination of high-fidelity photographic observations, massive amounts of different environment configurations and fast simulation speeds. In this paper we argue that research on training agents capable of complex reasoning can be simplified by decoupling from the requirement of high fidelity photographic observations. We present a suite of tasks requiring complex reasoning and exploration in continuous, partially observable 3D environments. The objective is to provide challenging scenarios and a robust baseline agent architecture that can be trained on mid-range consumer hardware in under 24h. Our scenarios combine two key advantages: (i) they are based on a simple but highly efficient 3D environment (ViZDoom) which allows high speed simulation (12000fps); (ii) the scenarios provide the user with a range of difficulty settings, in order to identify the limitations of current state of the art algorithms and network architectures. We aim to increase accessibility to the field of Deep-RL by providing baselines for challenging scenarios where new ideas can be iterated on quickly. We argue that the community should be able to address challenging problems in reasoning of mobile agents without the need for a large compute infrastructure.
Although plate tectonics has pushed the frontiers of geosciences in the past 50 years, it has legitimate limitations and among them we focus on both the absence of dynamics in the theory, and the difficulty of reconstructing tectonics when data is sparse. In this manuscript, we propose an anticipation experiment, proposing a singular outlook on plate tectonics in the digital era. We hypothesize that mantle convection models producing self-consistently plate-like behavior will capture the essence of the self-organisation of plate boundaries. Such models exist today in a preliminary fashion and we use them here to build a database of mid-ocean ridge and trench configurations. To extract knowledge from it we develop a machine learning framework based on Generative Adversarial Networks (GANs) that learns the regularities of the self-organisation in order to fill gaps of observations when working on reconstructing a plate configuration. The user provides the distribution of known ridges and trenches, the location of the region where observations lack, and our digital architecture proposes a horizontal divergence map from which missing plate boundaries are extracted. Our framework is able to prolongate and interpolate plate boundaries within an unresolved region, but fails to retrieve a plate boundary that would be completely contained in it. The attempt we make is certainly too early because geodynamic models need improvement and a larger amount of geodynamic model outputs, as independent as possible, is required. However, this work suggests applying such an approach to expand the capabilities of plate tectonics is within reach.
In this article, we address the problem of the classification of the health state of the colon's wall of mice, possibly injured by cancer with machine learning approaches. This problem is essential for translational research on cancer and is a priori challenging since the amount of data is usually limited in all preclinical studies for practical and ethical reasons. Three states considered including cancer, health, and inflammatory on tissues. Fully automated machine learning-based methods are proposed, including deep learning, transfer learning, and shallow learning with SVM. These methods addressed different training strategies corresponding to clinical questions such as the automatic clinical state prediction on unseen data using a pre-trained model, or in an alternative setting, real-time estimation of the clinical state of individual tissue samples during the examination. Experimental results show the best performance of 99.93% correct recognition rate obtained for the second strategy as well as the performance of 98.49% which were achieved for the more difficult first case.
We propose semantic grid, a spatial 2D map of the environment around an autonomous vehicle consisting of cells which represent the semantic information of the corresponding region such as car, road, vegetation, bikes, etc. It consists of an integration of an occupancy grid, which computes the grid states with a Bayesian filter approach, and semantic segmentation information from monocular RGB images, which is obtained with a deep neural network. The network fuses the information and can be trained in an end-to-end manner. The output of the neural network is refined with a conditional random field. The proposed method is tested in various datasets (KITTI dataset, Inria-Chroma dataset and SYNTHIA) and different deep neural network architectures are compared.
Using touch devices to navigate in virtual 3D environments such as computer assisted design (CAD) models or geographical information systems (GIS) is inherently difficult for humans, as the 3D operations have to be performed by the user on a 2D touch surface. This ill-posed problem is classically solved with a fixed and handcrafted interaction protocol, which must be learned by the user. We propose to automatically learn a new interaction protocol allowing to map a 2D user input to 3D actions in virtual environments using reinforcement learning (RL). A fundamental problem of RL methods is the vast amount of interactions often required, which are difficult to come by when humans are involved. To overcome this limitation, we make use of two collaborative agents. The first agent models the human by learning to perform the 2D finger trajectories. The second agent acts as the interaction protocol, interpreting and translating to 3D operations the 2D finger trajectories from the first agent. We restrict the learned 2D trajectories to be similar to a training set of collected human gestures by first performing state representation learning, prior to reinforcement learning. This state representation learning is addressed by projecting the gestures into a latent space learned by a variational auto encoder (VAE).
This chapter describes experimental and modeling work aiming at describing gaze patterns that are mutually exchanged by interlocutors during situated and task-directed face-to-face two-ways interactions. We will show that these gaze patterns (incl. blinking rate) are significantly influenced by the cognitive states of the interlocutors (speaking, listening, thinking, etc.), their respective roles in the conversation (e.g. instruction giver, respondent) as well as their social relationship (e.g. colleague, supervisor).
This chapter provides insights into the (micro-)coordination of gaze with other components of attention management as well as methodologies for capturing and modeling behavioral regularities observed in experimental data. A particular emphasis is put on statistical models, which are able to learn behaviors in a data-driven way.
We will introduce several statistical models of multimodal behaviors that can be trained on such multimodal signals and generate behaviors given perceptual cues. We will notably compare performances and properties of models which explicitly model the temporal structure of studied signals, and which relate them to internal cognitive states. In particular we study Semi-Hidden Markov Models and Dynamic Bayesian Networks and compare them to classifiers without sequential models (Support Vector Machines and Decision Trees).
We will further show that the gaze of conversational agents (virtual talking heads, speaking robots) may have a strong impact on communication efficiency. One of the conclusions we draw from these experiments is that multimodal behavioral models able to generate co-verbal gaze patterns should be designed with great care in order not to increase cognitive load. Experiments involving an impoverished or irrelevant control of the gaze of artificial agents (virtual talking heads and humanoid robots) have demonstrated its negative impact on communication (Garau, Slater, Bee, & Sasse, 2001).
We propose a method for human activity recognition from RGB data which does not rely on any pose information during test time, and which does not explicitly calculate pose information internally. Instead, a visual attention module learns to predict glimpse sequences in each frame. These glimpses correspond to interest points in the scene which are relevant to the classified activities. No spatial coherence is forced on the glimpse locations, which gives the module liberty to explore different points at each frame and better optimize the process of scrutinizing visual information.
Tracking and sequentially integrating this kind of unstructured data is a challenge, which we address by separating the set of glimpses from a set of recurrent tracking/recognition workers. These workers receive the glimpses, jointly performing subsequent motion tracking and prediction of the activity itself. The glimpses are soft-assigned to the workers, optimizing coherence of the assignments in space, time and feature space using an external memory module. No hard decisions are taken, i.e.~each glimpse point is assigned to all existing workers, albeit with different importance. Our methods outperform state-of-the-art methods on the largest human activity recognition dataset available to-date; NTU RGB+D Dataset, and on a smaller human action recognition dataset Northwestern-UCLA Multiview Action 3D Dataset.
In an autonomous vehicle setting, we propose a method for the estimation of a semantic grid, i.e. a bird's eye grid centered on the car's position and aligned in its driving direction, which contains high-level semantic information on the environment and its actors. Each grid cell contains a semantic label with divers classes, as for instance {Road, Vegetation, Building, Pedestrian, Car ...}.
We propose a hybrid approach, which combines the advantages of two different methodologies: we use Deep Learning to perform semantic segmentation on monocular RGB images with supervised learning from labeled groundtruth data. We combine these segmentations with occupancy grids calculated from LIDAR data using a generative Bayesian particle filter. The fusion itself is carried out with a deep network, which learns to integrate geometric information from the LIDAR with semantic information from the RGB data.
We tested our method on two datasets, namely the KITTI dataset, which is publicly available and widely used, and our own dataset obtained from with our own platform, a Renault ZOE equipped with a LIDAR and various sensors. We largely outperform baselines which calculate the semantic grid either from the RGB image alone or from LIDAR output alone, showing the interest of this hybrid approach.
This paper presents an architecture dedicated to the orchestration of high level abilities of a humanoid robot, such as a Pepper, which must perform some tasks as the ones proposed in the RoboCup@Home competition. We present the main abilities that a humanoid service robot should provide. We choose to build them based on recent methodologies linked to social navigation and deep learning. We detail the architecture, on how high level abilities are connected with low level sub-functions. Finally we present first experimental results with a Pepper humanoid.
We propose a fully automatic method for learning gestures on big touch devices in a potentially multi-user context. The goal is to learn general models capable of adapting to different gestures, user styles and hardware variations (e.g. device sizes, sampling frequencies and regularities).
Based on deep neural networks, our method features a novel dynamic sampling and temporal normalization component, transforming variable length gestures into fixed length representations while preserving finger/surface contact transitions, that is, the topology of the signal. This sequential representation is then processed with a convolutional model capable, unlike recurrent networks, of learning hierarchical representations with different levels of abstraction.
To demonstrate the interest of the proposed method, we introduce a new touch gestures dataset with 6758 gestures performed by 27 people, which is, up to our knowledge, the first of its kind: a publicly available multi-touch gesture dataset for interaction. We also tested our method on a standard dataset in symbolic touch gesture recognition, the MMG dataset, outperforming the state of the art and reporting close to perfect performance.
Authoring virtual terrains presents a challenge and there is a strong need for authoring tools able to create realistic terrains with simple user-inputs and with high user control. We propose an example-based authoring pipeline that uses a set of terrain synthesizers dedicated to specific tasks.
Each terrain synthesizer is a Conditional Generative Adversarial Network trained by using real-world terrains and their sketched counterparts. The training sets are built automatically with a view that the terrain synthesizers learn the generation from features that are easy to sketch. During the authoring process, the artist first creates a rough sketch of the main terrain features, such as rivers, valleys and ridges, and the algorithm automatically synthesizes a terrain corresponding to the sketch using the learned features of the training samples. Moreover, an erosion synthesizer can also generate terrain evolution by erosion at a very low computational cost. Our framework allows for an easy terrain authoring and provides a high level of realism for a minimum sketch cost. We show various examples of terrain synthesis created by experienced as well as inexperienced users who are able to design a vast variety of complex terrains in a very short time.
We propose a new spatio-temporal attention based mechanism for human action recognition able to automatically attend to most important human hands and detect the most discriminative moments in an action. Attention is handled in a recurrent manner employing Recurrent Neural Network (RNN) and is fully-differentiable. In contrast to standard soft-attention based mechanisms, our approach does not use the hidden RNN state as input to the attention model. Instead, attention distributions are drawn using external information: human articulated pose. We performed an extensive ablation study to show the strengths of this approach and we particularly studied the conditioning aspect of the attention mechanism.
We evaluate the method on the largest currently available human action recognition dataset, NTU-RGB+D, and report state-of-the-art results. Another advantage of our model are certains aspects of explanability, as the spatial and temporal attention distributions at test time allow to study and verify on which parts of the input data the method focuses.
Text line detection and localization is a crucial step for full page document analysis, but still suffers from heterogeneity of real life documents. In this paper, we present a new approach for full page text recognition. Localization of the text lines is based on regressions with Fully Convolutional Neural Networks and Multidimensional Long Short-Term Memory as contextual layers.
In order to increase the efficiency of this localization method, only the position of the left side of the text lines are predicted. The text recognizer is then in charge of predicting the end of the text to recognize. This method has shown good results for full page text recognition on the highly heterogeneous Maurdor dataset.
Graphs and hyper-graphs are frequently used to recognize complex and often non-rigid patterns in computer vision, either through graph matching or point-set matching with graphs. Most formulations resort to the minimization of a difficult energy function containing geometric or structural terms, frequently coupled with data attached terms involving appearance information. Traditional methods solve the minimization problem approximately, for instance re- sorting to spectral techniques. In this paper, we deal with the spatio-temporal data, for a concrete example, human actions in video sequences. In this context, we first make three realistic assumptions: (i) causality of human movements; (ii) sequential nature of human movements; and (iii) one-to-one mapping of time instants. We show that, under these assumptions, the correspondence problem can be decomposed into a set of subproblems such that each subproblem can be solved recursively in terms of the others, and hence an efficient exact minimization algorithm can be derived using dynamic programming approach. Secondly, we propose a special graphical structure which is elongated in time. We argue that, instead of approximately solving the original problem, a solution can be obtained by exactly solving an approximated problem. An exact minimization algorithm is derived for this structure and successfully applied to action recognition in two settings: video data and Kinect coordinate data.
We evaluate here the ability of statistical models, namely Hidden Markov Models (HMMs) and Dynamic Bayesian Networks (DBNs), in capturing the interplay and coordination between multimodal behaviors of two individuals involved in a face-to-face interaction. We structure the intricate sensory-mot or coupling of the joint multimodal scores by segmenting the whole interaction into so-called interaction units (IU). We show that the proposed statistical models are able to capture the natural dynamics of the interaction and that DBNs are particularly suitable for reproducing original distributions of so-called coordination histograms.
Evaluating the performance of computer vision algorithms is classically done by reporting classification error or accuracy, if the problem at hand is the classification of an object in an image, the recognition of an activity in a video or the categorization and labeling of the image or video. If in addition the detection of an item in an image or a video, and/or its localization are required, frequently used metrics are Recall and Precision, as well as ROC curves. These metrics give quantitative performance values which are easy to understand and to interpret even by non-experts. However, an inherent problem is the dependency of quantitative performance measures on the quality constraints that we need impose on the detection algorithm. In particular, an important quality parameter of these measures is the spatial or spatio-temporal overlap between a ground-truth item and a detected item, and this needs to be taken into account when interpreting the results.
We propose a new performance metric addressing and unifying the qualitative and quantitative aspects of the performance measures. The performance of a detection and recognition algorithm is illustrated intuitively by performance graphs which present quantitative performance values, like Recall, Precision and F-Score, depending on quality constraints of the detection. In order to compare the performance of different computer vision algorithms, a representative single performance measure is computed from the graphs, by integrating out all quality parameters. The evaluation method can be applied to different types of activity detection and recognition algorithms. The performance metric has been tested on several activity recognition algorithms participating in the ICPR 2012 HARL competition.
Object recognition, human pose estimation and scene recognition are applications which are frequently solved through a decomposition into a collection of parts. The resulting local representation has significant advantages, especially in the case of occlusions and when the subject is non-rigid. Detection and recognition require modelling the appearance of the different object parts as well as their spatial layout. This representation has been particularly successful in body part estimation from depth images. Integrating the spatial layout of parts may require the minimization of complex energy functions. This is prohibitive in most real world applications and therefore often omitted. However, ignoring the spatial layout puts all the burden on the classifier, whose only available information is local appearance. We propose a new method to integrate spatial layout into parts classification without costly pairwise terms during testing. Spatial relationships are exploited in the training algorithm, but not during testing. As with competing methods, the proposed method classifies pixels independently, which makes real-time processing possible. We show that training a classifier with spatial relationships increases generalization performance when compared to classical training minimizing classification error on the training set. We present an application to human body part estimation from depth images.
Modeling multimodal perception-action loops in face-to- face interactions is a crucial step in the process of building sensory-motor behaviors for social robots or users-aware Embodied Conversational Agents (ECA). In this paper, we compare trainable behavioral models based on sequential models (HMMs) and classifiers (SVMs and Decision Trees) inherently inappropriate to model sequential aspects. These models aim at giving pertinent perception/action skills for robots in order to generate optimal actions given the perceived actions of others and joint goals. We applied these models to parallel speech and gaze data collected from interacting dyads. The challenge was to predict the gaze of one subject given the gaze of the interlocutor and the voice activity of both. We show that Incremental Discrete HMM (IDHMM) generally outperforms classifiers and that injecting input context in the modeling process significantly improves the performances of all algorithms.
Modeling multimodal face-to-face interaction is a crucial step in the process of building social robots or users-aware Embodied Conversational Agents (ECA). In this context, we present a novel approach for human behavior analysis and generation based on what we called “Incremental Discrete Hidden Markov Model” (IDHMM). Joint multimodal activities of interlocutors are first modeled by a set of DHMMs that are specific to supposed joint cognitive states of the interlocutors. Respecting a task-specific syntax, the IDHMM is then built from these DHMMs and split into i) a recognition model that will determine the most likely sequence of cognitive states given the multimodal activity of the interlocutor, and ii) a generative model that will compute the most likely activity of the speaker given this estimated sequence of cognitive states. Short-Term Viterbi (STV) decoding is used to incrementally recognize and generate behavior. The proposed model is applied to parallel speech and gaze data of interacting dyads.
In this paper, we present a novel approach for supervised codebook learning and optimization for bag of words models. This type of models is frequently used in visual recognition tasks like object class recognition or human action recognition. An entity is represented as a histogram of codewords, which are traditionally clustered with unsupervised methods like \textit{k}-means or random forests, and then classified in a supervised way. We propose a new supervised method for joint codebook creation and class learning, which learns the cluster centers of the codebook in a goal-directed way using the class labels of the training set. As a result, the codebook is highly correlated to the recognition problem, leading to a more discriminative codebook. We propose two different learning algorithms, one based on error backpropagation and one based on cluster label reassignment. We apply the proposed method to human action recognition from video sequences and evaluate it on the KTH dataset, reporting very promising results. The proposed technique allows to improve the discriminative power of an unsupervised learned codebook, or to keep the discriminative power while decreasing the size of the learned codebook, thus decreasing the computational complexity due to the nearest neighbor search.
A new mesh optimization framework for 3D triangular surface meshes is presented, which formulates the task as an energy minimization problem in the same spirit as in Hoppe et al. [1]. The desired mesh properties are controlled through a global energy function including data attached terms measuring the fidelity to the original mesh, shape potentials favoring high quality triangles and connectivity as well as budget terms controlling the sampling density. The optimization algorithm modifies mesh connectivity as well as the vertex positions. Solutions for the vertex repositioning step are obtained by a discrete graph cut algorithm examining global combinations of local candidates. Results on various 3D meshes compare favorably to recent state-of-the-art algorithms. Applications consist in optimizing triangular meshes and in simplifying meshes, while maintaining high mesh quality. Targeted areas are the improvement of the accuracy of numerical simulations, the convergence of numerical schemes, improvements of mesh rendering (normal field smoothness) or improvements of the geometric prediction in mesh compression techniques.
Activity recognition in video sequences is a difficult problem due to the complex characteristics of human articulated motion and its large variations. It requires motion estimation, which involves the separation of motion and visual appearance information, the suppression of irrelevant background clutter and background motion, the separation of motion belonging to different people, and the creation of models describing actions. In this talk we will briefly describe the different frameworks for action recognition, based on background subtraction and on space-time interest points, and we will focus and structured and on semi-structured models. These models attempt to bridge the gap between the rich descriptive power of fully structured models constructed from sets of local features and the convenience and the power of machine learning algorithms, which are mostly based on unstructured features embedded in vector spaces. Semi-structured models proceed by translating structured information into unstructured information, while structured models keep a full representation. As an example we will deal with graphs and graph matching algorithms. Hierarchical representations and parts based models will be investigated, which allow to decompose complex activities into smaller parts of less sophisticated elementary actions or elementary descriptors.
Graph matching is one of the principal methods to formulate the correspondence between two set of points in computer vision and pattern recognition. Most formulations are based on the minimization of a difficult energy function which is known to be NP-hard. Traditional methods solve the minimization problem approximately. In this paper, we derive an exact minimization algorithm and successfully applied to action recognition in videos. In this context, we take advantage of special properties of the time domain, in particular causality and the linear order of time, and propose a new spatio-temporal graphical structure. We show that a better solution can be obtained by exactly solving an approximated problem instead of approximately solving the original problem.
We propose in this paper a fully automated deep model, which learns to classify human actions without using any prior knowledge. The first step of our scheme, based on the extension of Convolutional Neural Networks to 3D, automatically learns spatio-temporal features. A Recurrent Neural Network is then trained to classify each sequence considering the temporal evolution of the learned features for each timestep. Experimental results on the KTH dataset show that the proposed approach outperforms existing deep models, and gives comparable results with the best related works.
We present a new method for blind document bleed through removal based on separate Markov Random Field (MRF) regularization for the recto and for the verso side, where separate priors are derived from the full graph. The segmentation algorithm is based on Bayesian Maximum a Posteriori (MAP) estimation. The advantages of this separate approach are the adaptation of the prior to the contents creation process (e.g. superimposing two hand written pages), and the improvement of the estimation of the recto pixels through an estimation of the verso pixels covered by recto pixels; Moreover, the formulation as a binary labeling problem with two hidden labels per pixels naturally leads to an efficient optimization method based on the minimum cut/maximum flow in a graph. The proposed method is evaluated on scanned document images from the 18th century, showing an improvement of character recognition results compared to other restoration methods.
We introduce a new causal hierarchical belief network for image segmentation. Contrary to classical tree structured (or pyramidal) models, the factor graph of the network contains cycles. Each level of the hierarchical structure features the same number of sites as the base level and each site on a given level has several neighbors on the parent level. Compared to tree structured models, the (spatial) random process on the base level of the model is stationary which avoids known drawbacks, namely visual artifacts in the segmented image. We propose different parameterizations of the conditional probability distributions governing the transitions between the image levels. A parametric distribution depending on a single parameter allows the design of a fast inference algorithm on graph cuts, whereas for arbitrary distributions, we propose inference with loopy belief propagation. The method is evaluated on scanned documents, showing an improvement of character recognition results compared to other methods.
Evaluation of object detection algorithms is a non-trivial task: a detection result is usually evaluated by comparing the bounding box of the detected object with the bounding box of the ground truth object. The commonly used precision and recall measures are computed from the overlap area of these two rectangles. However, these measures have several drawbacks: they don't give intuitive information about the proportion of the correctly detected objects and the number of false alarms, and they cannot be accumulated across multiple images without creating ambiguity in their interpretation. Furthermore, quantitative and qualitative evaluation is often mixed resulting in ambiguous measures.
In this paper we propose an approach to evaluation which tackles these problems. The performance of a detection algorithm is illustrated intuitively by performance graphs which present object level precision and recall depending on constraints on detection quality. In order to compare different detection algorithms, a representative single performance value is computed from the graphs. The evaluation method can be applied to different types of object detection algorithms. It has been tested on different text detection algorithms, among which are the participants of the Image Eval text detection competition.
Evaluation of object detection algorithms is a non-trivial task: a detection result is usually evaluated by comparing the bounding box of the detected object with the bounding box of the ground truth object. The commonly used precision and recall measures are computed from the overlap area of these two rectangles. However, these measures have several drawbacks: they don't give intuitive information about the proportion of the correctly detected objects and the number of false alarms, and they cannot be accumulated across multiple images without creating ambiguity in their interpretation. Furthermore, quantitative and qualitative evaluation is often mixed resulting in ambiguous measures.
In this paper we propose a new approach which tackles these problems. The performance of a detection algorithm is illustrated intuitively by performance graphs which present object level precision and recall depending on constraints on detection quality. In order to compare different detection algorithms, a representative single performance value is computed from the graphs. The influence of the test database on the detection performance is illustrated by performance/generality graphs. The evaluation method can be applied to different types of object detection algorithms. It has been tested on different text detection algorithms, among which are the participants of the ICDAR 2003 text detection competition.
@Article{WolfIJDAR2006,
Author = {C. Wolf and J.-M. Jolion},
Title = {Object count/Area Graphs for the Evaluation of Object Detection and Segmentation Algorithms},
Journal = {International Journal on Document Analysis and Recognition},
year = {2006},
volume = {8},
number = {4},
pages = {280-296}
}
@Article{WolfPAA03,
Author = {C. Wolf and J.-M. Jolion},
Title = {Extraction and {R}ecognition of {A}rtificial {T}ext in {M}ultimedia {D}ocuments},
Journal = {Pattern {A}nalysis and {A}pplications},
year = {2003},
volume = {6},
number = {4},
pages = {309-326}
}
@InProceedings{WolfICPR2002V,
Author = {C. Wolf and J.-M. Jolion and F. Chassaing},
Title = {Text {L}ocalization, {E}nhancement and {B}inarization in {M}ultimedia {D}ocuments},
BookTitle = {Proceedings of the {I}nternational {C}onference on {P}attern {R}ecognition},
Volume = {2},
Pages = {1037-1040},
year = 2002,
}
@InProceedings{WolfICPR2002M,
Author = {C. Wolf and D. Doermann},
Title = {Binarization of {L}ow {Q}uality {T}ext using a {M}arkov {R}andom {F}ield {M}odel},
BookTitle = {Proceedings of the {I}nternational {C}onference on {P}attern {R}ecognition},
Volume = {3},
Pages = {160-163},
year = 2002,
}
Our team from the University of Maryland and INSA de Lyon participated in the feature extraction evaluation with overlay text features and in the search evaluation with a query retrieval and browsing system. For search we developed a weighted query mechanism by integrating 1) text (OCR and speech recognition) content using full text and n-grams through the MG system, 2) color correlogram indexing of image and video shots reported last year in TREC, and 3) ranked versions of the extracted binary features. A command line version of the interface allows users to formulate simple queries, store them and use weighted combinations of the simple queries to generate compound queries.
One novel component of our interactive approach is the ability for the users to formulate dynamic queries previously developed for database applications at Maryland. The interactive interface treats each video clip as visual object in a multi-dimensional space, and each "feature" of that clip is mapped to one dimension. The user can visualize any two dimensions by placing any two features on the horizontal and vertical axis with additional dimensions visualized by adding attributes to each object.
Interest point detectors are used in computer vision to detect image points with special properties, which can be geometric (corners) or non-geometric (contrast etc.). Gabor functions and Gabor filters are regarded as excellent tools for feature extraction and texture segmentation. This article presents methods how to combine these methods for content based image retrieval and to generate a textural description of images. Special emphasis is devoted to distance measure texture descriptions. Experimental results of a query system are given.
This work was supported in part by the Austrian Science Foundation (FWF) under grant S-7002-MAT.
@InProceedings{WolfICPR2000,
Author = {C. Wolf and J.M. Jolion and W. Kropatsch and H. Bischof},
Title = {Content {B}ased {I}mage {R}etrieval using {I}nterest {P}oints and {T}exture {F}eatures},
BookTitle = {Proceedings of the {I}nternational {C}onference on {P}attern {R}ecognition},
Volume = {4},
Pages = {234-237},
year = 2000,
}
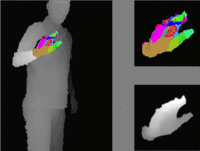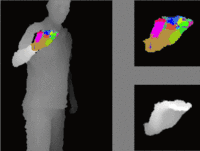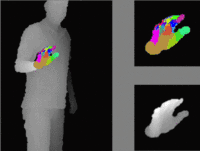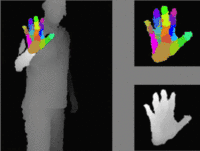{kind=link}